
De Nieuwe Taalgids. Jaargang 69
(1976)– [tijdschrift] Nieuwe Taalgids, De–
[pagina 426]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De leesbaarheid van basisschoolteksten. Objectieve ordeningscriteria voor instructieve tekstenSamenvattingIn dit artikel worden een vuistregel en twee leesbaarheidsformules gepresenteerd voor objectieve ordening van de leesbaarheid van instructieve teksten voor lezers van de derde tot en met de zesde klas van de basisschool. De vuistregel en de formules zijn eenvoudig hanteerbaar. Met de oordelen van ruim 100 onderwijzers en met de clozescores van ruim 1500 leerlingen als criteria voor leesbaarheid werden een aantal tekstkenmerken geanalyseerd, waarvan ‘verschillende moeilijke lange woorden’ de belangrijkste bleek. Tenslotte werd geconcludeerd dat de theoretische validiteit van de clozeprocedure minstens even goed is als van andere begriptesten (Het onderzoek was een deel van S.V.O.-project 0-275 ‘Receptieve taalbeheersing’). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1. InleidingIn het onderzoek is het ons te doen om een ‘objectief’ ordeningscriterium te vinden voor de moeilijkheidsgraad ofwel de leesbaarheid van instructieve teksten. De ordening kan op verschillende manieren plaatsvinden: via het oordeel van deskundigen (onderwijzers), via het oordeel van lezers (leerlingen van de derde tot en met zesde klas van basisscholen) of via bestaande leesbaarheidsformules (de formules van Douma en Brouwer).Ga naar voetnoot1 Hebben we eenmaal meer zekerheid over de betrouwbaarheid van de ordening, dan gaan we na of de tekst ‘objectieve’ kenmerken heeft, die deze ordening weerspiegelen. In ons onderzoek gebruikten we ‘instructieve’ teksten die we ‘geschikt’ achtten voor leerlingen van de derde tot en met de zesde klas van de basisschool. Ter verduidelijking dienen eerst de termen ‘instructief’ en ‘geschikt’ te worden toegelicht. De term ‘instructief’ is ruim opgevat: het gaat om teksten waarvan de inhoud dichtbij de betekenis staat. In litteraire teksten is dit niet het geval: zo weet iedereen dat het verhaal over Reynaert de Vos meer betekent dan de inhoud in eerste instantie aangeeft. In onze verzameling teksten zijn wel enkele verhaaltjes opgenomen, naast wat meer betogende teksten, maar deze verhaaltjes zijn ondubbelzinnig. Ze zijn een verslag van gebeurtenissen en als zodanig instructief. Om de term ‘geschikt’ toe te lichten zullen we de leessituatie globaal beschrijven. Er kunnen veel redenen zijn, waarom iemand een tekst het predikaat ‘leesbaar’ of ‘onleesbaar’ meegeeft. Deze redenen kunnen op een drietal gebieden liggen:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 427]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Alle hiervoor genoemde factoren kunnen stuk voor stuk voor de lezer de beweegreden zijn om van een tekst te zeggen dat hij onleesbaar is. Hoe deze factoren samenhangen weten we nog niet. Voorlopig volstaan we met de constatering dat de leesbaarheid een functie is van factoren in de lezer, factoren in de tekst, en factoren in de leessituatie. We kunnen nu de probleemstelling als volgt formuleren: hoe kan men vaststellen welke tekstkenmerken van een instructieve tekst bepalen of die tekst optimaal leesbaar is voor lezers van de basisschool, in een gegeven leersituatie, in een gegeven klas. En hoe kan deze vaststelling worden gebruikt om de leesbaarheid van een instructieve tekst voor een lezer of lezersgroep te voorspellen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. Afhankelijke variabelenDe oordelen van de onderwijzers werden verkregen via enquêtes in Breda en in Utrecht: voor elke tekst moesten de onderwijzers het oordeel ‘te moeilijk’, ‘geschikt’ of ‘te gemakkelijk’ geven. De oordelen van de leerlingen werden verkregen door clozetests: in de teksten werd om de zeven woorden een woord weggelaten, dat door de leerlingen moest worden ingevuld. Om het eerste weg te laten woord werd geloot. Het gebruik van clozetesten is gebaseerd op de volgende vooronderstellingen. Naarmate ten eerste het onderwerp bekender is voor de lezer en naarmate ten tweede het taalgebruik beter aansluit bij dat van de lezer, is hij beter in staat de goede woorden op de open plaatsen in te vullen. Met andere woorden: hoe redundanter een tekst voor iemand is, des te gemakkelijker zal het voor hem zijn de systematisch verminkte tekst op de goede manier te herstellen. Deze manier om leesbaarheid van teksten te meten is in 1953 ontwikkeld door TaylorGa naar voetnoot2 en later veelvuldig gebruikt, o.a. door Bormuth.Ga naar voetnoot3 Door de onderwijzersoordelen en de clozescores konden we de teksten rangschikken in moeilijkheid. We gebruikten de teksten uit het onderzoek van Zondervan & Schellens.Ga naar voetnoot4 De clozetesten namen we af op zeven scholen in Breda. De volgende stap was dan de analyse van de eigenschappen van de teksten: welke eigenschappen maken een tekst moeilijk of gemakkelijk. Deze eigenschappen zijn de onafhankelijke of verklarende variabelen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. Onafhankelijke variabelenIn ons onderzoek beperkten we ons tot de tekstkenmerken als verklarende variabelen voor de leesbaarheid, zoals die geoperationaliseerd werd door de afhankelijke variabele. We wilden aan de tekst zelf kunnen zien of hij als instructieve tekst niet te moeilijk was voor kinderen in een bepaalde klas van de basisschool. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 428]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bij de beschrijving en de keuze van de tekstvariabelen maakten we gebruik van de volgende begrippen: lettergreep, woord, zin, hoofdzin, bijzin, gezegde, persoonsvorm, hulpwerkwoord, voltooid deelwoord, enz. Tenzij uitdrukkelijk anders vermeld, komt de betekenis van de genoemde begrippen overeen met de betekenis die ze hebben in de traditionele grammatica. In principe gebruikten we dezelfde tekstkenmerken als Van Hauwermeiren in zijn dissertatie.Ga naar voetnoot5 Zijn keuze berust op de factoranalyse van onder andere Stolurow & NewmanGa naar voetnoot6 en op de gegevens uit het Amerikaanse leesbaarheidsonderzoek. Wij selecteerden uit Van Hauwermeirens lijst de belangrijkste. Vanzelfsprekend behoren daartoe ook de geijkte variabelen gemiddelde woord- en zinslengte, bekend uit de leesbaarheidsformule van Rudolf FleschGa naar voetnoot7 en de hierop gebaseerde Nederlandse publicaties van Douma, Brouwer, Van der Werff en De Groot.Ga naar voetnoot8 Douma en Brouwer maakten aanpassingen van de formule van Flesch voor het Nederlands; Van der Werff en De Groot gebruikten de resultaten van het Amerikaanse leesbaarheidsonderzoek voor hun richtlijnen voor leesbaar schrijven. Dit laatste is een ontoelaatbare toepassing van het leesbaarheidsonderzoek. Mag in het algemeen gelden dat men goed leesbare teksten van slecht leesbare kan onderscheiden door naar de gemiddelde woord- en zinslengte te kijken, men mag deze regel niet omkeren en beweren dat een tekst leesbaarder wordt naarmate men meer korte woorden en zinnen schrijft. De relatie tussen leesbaarheid enerzijds en verklarende variabelen anderzijds is niet equivalent. Bij leesbaar schrijven spelen veel meer variabelen een rol dan de twee uit de Fleschformule. De samenhang is complex en het onderzoek ernaar bevindt zich nog in een beginstadium. Als eerste factor in ons leesbaarheidsonderzoek namen we de gemiddelde woordlengte in lettergrepen (X1). Hierbij gingen we ervan uit dat de moeilijkheid van een tekst in de basisschool voor een groot deel bepaald wordt door moeilijke woorden. Volgens de wet van Zipf en getuige de woordfrequentielijsten, waaruit is af te lezen dat de woordfrequentie omgekeerd evenredig is met de woordlengte, kan de woordmoeilijkheid voor een groot deel worden uitgedrukt in woordlengte. Onder woord verstaan wij in dit artikel elke opeenvolging van letters of cijfers, voorafgegaan en gevolgd door een witspatie. Verbindingen als binnen- en buitenland hebben we dus als drie woorden geteld. Vormen van scheidbaar samengestelde werkwoorden als afslaan tellen in gescheiden positie als twee woorden. Bijvoorbeeld:
telt vijf woorden. Het tellen van woorden en lettergrepen levert nu over het algemeen geen problemen meer op, behalve bij verkortingen en telwoorden in cijfers. We spreken hiervoor af dat verkortingen als n.a.v., o.a. en b.b.h.h. als één woord tellen en respectievelijk drie, twee en vier lettergrepen tellen. Bij tel- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 429]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
woorden in cijfers telt men de lettergrepen die men bij het uitspreken ervan hoort. De factor X1 berekent men als volgt: deel het aantal lettergrepen van de betrokken passage door het aantal woorden van die passage. Als tweede factor namen we de gemiddelde zinslengte in woorden (X13). Hierbij gingen we ervan uit dat de syntactische complexiteit van een tekst kan worden uitgedrukt in de lengte van de zinnen. Bovendien kon blijken of er enige statistische grond is voor een aanpassing van de Flesch-Reading-Ease-formule voor het Nederlands. De zinsgrenzen worden enerzijds bepaald door een hoofdletter na een punt en anderzijds door een punt, een puntkomma, een dubbele punt, een uitroepteken en een vraagteken. De factor X13 berekent men als volgt: deel het aantal woorden van een passage door het aantal zinnen van die passage. Als derde factor namen we een iets genuanceerder maat dan de lengte van de zin: de gemiddelde lengte van de T-unit in woorden (X2). Het tellen van T-units is het tellen van minimale punctuatie-eenheden. In de meeste gevallen komen de grenzen van de T-units overeen met de zinsgrenzen. De zinsgrenzen worden echter genegeerd in geval van nevengeschikte hoofdzinnen en in geval van onderschikking van hoofd- en bijzin(nen). Dus:
telt als twee T-units.
telt als één T-unit.
De gemiddelde lengte van de T-unit wordt als volgt berekend: deel het aantal woorden van een passage door het aantal T-units van die passage. Als vierde, vijfde en zesde factor namen we het percentage substantieven (X3), het percentage voorzetsels (X4) en het percentage persoonlijke voornaamwoorden (X12). Hierbij gingen we ervan uit dat de mate waarin deze woordsoorten in een tekst aanwezig zijn bepalend is voor de leesbaarheid van een tekst. De factoren berekent men als volgt: tel de woordsoort per tekstpassage en deel dit getal door het aantal woorden van die passage; vermenigvuldig deze breuk met honderd. Als zevende en achtste factor namen we weer twee woordmoeilijkheidsfactoren: het percentage éénlettergrepige woorden (X11), en het percentage verschillende ‘moeilijke lange woorden’ (X5). Dit zijn woorden met meer dan drie lettergrepen die niet voorkomen in de woordenlijst die als bijlage 3 is opgenomen. Alleen het aantal verschillende ‘moeilijke lange woorden’ in een tekstpassage is geteld. Deze twee factoren berekent men als volgt: tel de woordsoort per tekstpassage en deel dit getal door het aantal woorden van die passage; vermenigvuldig deze breuk met honderd. Vervolgens namen we factoren die evenals de eerder genoemde gemiddelde | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 430]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
zinslengte staan voor de syntactische complexiteit: het percentage persoonsvormen (X6), het percentage hulpwerkwoorden (X7), het percentage bijzinnen van het aantal T-units (X8) en het percentage enkelvoudige zinnen van het aantal T-units (X14). De factor X6 berekent men als volgt: tel het aantal persoonsvormen van een passage en deel dit getal door het aantal woorden van die passage; vermenigvuldig deze breuk met honderd. Bij het bepalen van het percentage hulpwerkwoorden is het nodig te omschrijven wat wij precies hebben geteld als hulpwerkwoord (in de zinnen (4) tot en met (8) zijn de hulpwerkwoorden gecursiveerd)Ga naar voetnoot9:
Het percentage hulpwerkwoorden berekent men als volgt: tel het aantal hiervoor omschreven hulpwerkwoorden van een passage en deel dit getal door het aantal woorden van die passage; vermenigvuldig deze breuk met honderd. De factoren X8 en X14 berekent men als volgt: tel het aantal bijzinnen of enkelvoudige zinnen van een passage en deel dit getal door het aantal T-units van die passage; vermenigvuldig deze breuk met honderd. Tenslotte hebben we overeenkomstig de recente studie van Van HauwermeirenGa naar voetnoot10 de zogenaamde tang- of klemconstructie als verklarende variabele bij ons leesbaarheidsonderzoek betrokken. Een tangconstructie is elke verbinding van woorden of woordgroepen die direct naast elkaar kunnen voorkomen in een zin, en die bovendien door andere woorden uit elkaar geplaatst kunnen worden. Voorbeelden van tangconstructies staan in de zinnen (9) tot en met (12), waarbij wij de grijpers van de tangen cursiveerden. In ons onderzoek hebben wij twee factoren met betrekking tot de tangconstructie opgenomen: het percentage tangen (X9) en de gemiddelde tanglengte (X10). Hierbij gingen we ervan uit dat het uit elkaar plaatsen van twee bij elkaar horende woorden of woordgroepen in een tekst de moeilijkheid van die tekst beïnvloedt: hoe verder de twee grijpers van een tang uit elkaar staan, des te groter is de spanning van die tang. De spanning van de tang in de hoofdzin wordt niet alleen bepaald door het aantal woorden in die tang, maar ook door de binding tussen de grijpers van de tang. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 431]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De spanning tussen heeft en gewerkt in zin (9) is veel groter dan die tussen is en om u aan te vallen in zin (10). Daarnaast wordt in de ene tang de spanning al bij de eerste grijper opgeroepen, zoals in zin (11) en in de andere pas in de tweede grijper, zoals in zin (12). Deze oppervlakkige interpretaties van spanningen in de tang hebben wij nog niet kunnen vertalen in objectieve, telbare eenheden. Bij het tellen van de tangconstructies en het aantal woorden in de tang deden zich nog enkele problemen voor. Allereerst werden alleen die tangen geteld waarvan de grijpers ook werkelijk gescheiden waren door één of meer woorden. Vervolgens leidt samentrekking in nevengeschikte zinnen er soms toe dat de eerste of de tweede grijper van de tang in de tweede, nevengeschikte zin wordt weggelaten. Ook de woorden tussen de grijper worden soms niet herhaald. In zin (13) is de eerste grijper wordt een keer weggelaten.
We hebben in geval van samentrekking alleen díe woorden in de tang geteld die er werkelijk staan en slechts dan, als alleen de eerste grijper is weggelaten (en dus nooit als ook de tweede grijper is weggelaten). Ook alleen dan werd in de tweede zin de tang geteld. In zin (13) werden de woorden in de tang gecursiveerd. Binnen een tangconstructie kan nog een tweede en daarin nog een derde, enzovoort, tang gevormd worden. In dergelijke gevallen hebben we alle woorden tussen de grijpers van de meest omvattende tang slechts eenmaal geteld voor de factor gemiddelde tanglengte, ook als een tweede of derde ingesloten tang voorkwamen. Wel werden in die gevallen alle tangen geteld. De factor X9 berekent men als volgt: tel het aantal tangconstructies van een passage en deel dit getal door het aantal woorden van die passage; vermenigvuldig deze breuk met honderd. De factor X10 berekent men door het aantal woorden tussen de grijpers van de tangen uit een passage te delen door het aantal tangen van die passage. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4. Controle op de invloed van potentiële variabelenIn ons onderzoek is de invloed van de volgende potentiële variabelen tot nul gereduceerd: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
a. de invloed op het gebied van de lezer met zijn leesvaardigheidsniveau en zijn kennis van de wereld.Deze invloed hielden we onder controle door de gebruikelijke indeling in jaarniveau's aan te houden. Omdat we meenden dat er van begrijpend lezen pas in | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 432]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
de derde klas van de basisschool enigszins sprake kon zijn, hebben we de eerste en tweede klassen, waar voornamelijk het technisch lezen geoefend wordt, niet laten meedoen. We kozen derde tot en met zesde klassers. Van de zes meetellende scholen waren er in totaal 347 derdeklassers, 366 vierdeklassers, 407 vijfdeklassers en 411 zesdeklassers. In totaal dus 1531 leerlingen van zes katholieke basisscholen in Breda. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
b. de invloed op het gebied van de lezer met zijn persoonskenmerken en zijn persoonlijke smaak.Deze invloed hielden we onder controle door te werken met groepen van voldoende grootte: het totaal aantal leerlingen van elk jaarniveau werd aselect in ongeveer even grote groepen verdeeld, zodat er groepen van ongeveer 50 à 55 leerlingen ontstonden. Alle leerlingen in zo'n groep kregen dezelfde clozetesten. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
c. de invloed op het gebied van de setting van het communicatiegebeuren.Deze invloed hielden we onder controle door niet te werken met klassen, maar met de groepen van 50 à 55 peronen, die werden samengesteld uit leerlingen uit alle klassen (per jaarniveau). De instructie was voor alle leerlingen gelijk. De invloed van het leereffect van een eerste op een tweede clozetest werd onder controle gehouden door binnen de groepen van 50 à 55 personen systematisch te variëren met de volgorde waarin de testen aan de leerlingen werden gegeven. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5. De resultatena. inleidingWanneer men gebruik maakt van empirische onderzoeksmethoden is de statistiek een onmisbare hulpdiscipline. Bij de meeste neerlandici ontbreekt echter de meest elementaire kennis daarvan. Omdat wij op het instituut ‘De Vooys’ vinden dat het ontbreken van elementaire kennis van het vak onderzoeksmethoden een gebrek is van de opleiding tot neerlandicus, hebben wij - zij het met enige schroom - een meerjarige introduktie in de curricula opgenomen. Hiermee hopen we te bereiken dat de Utrechtse neerlandici met meer begrip zullen oordelen over allerlei zogenaamde psychometrische zaken het vak betreffende, zoals ‘objectieve studietoetsen’, het meten van luistervaardigheid of het beoordelen van samenvattingen. We hebben in dit artikel gepoogd de gebruikte statistiek tot een minimum te beperken en zo duidelijk mogelijk te presenteren.Ga naar voetnoot11 Een leek op dit gebied zal echter heel wat op gezag van de schrijvers moeten accepteren. Bij de discussie van de resultaten probeerden we alles weer in zo eenvoudig mogelijke vorm te presenteren. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 433]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
b. empirische validiteitMultiple lineaire regressieGa naar voetnoot12 leverde als eerste resultaat de mate van de empirische validiteit van de gekozen criteria voor leesbaarheid van teksten voor de basisschool. In een kruisvalidatie vergeleken we de onderwijzersoordelen uit Utrecht met die van Breda. Daarna vergeleken we de onderwijzersoordelen met de gemiddelde clozescores per leesvaardigheidsniveau. Tenslotte vergeleken we onze criteria met de formules van Douma en Brouwer. Deze vergelijkingen zijn uitgedrukt in correlatiecoëfficienten. (Zie bijlage 1 voor correlatiematrix 1) Een perfekte positieve correlatie is + 1.00 (positief: hoe groter het verloop in de ene variabele, des te groter het verloop in de andere variabele); een perfekte negatieve correlatie is -1.00 (negatief; hoe groter het verloop in de ene variabele, des te kleiner het verloop in de andere variabele). Is de correlatie nul, dan is er geen lineair verband tussen de onderzochte grootheden. In de praktijk liggen de bruikbare correlatiecoëfficienten boven de .50 of onder de -.50. De correlatiecoëfficienten geven weliswaar een indicatie van de empirische validiteit, maar alle met elkaar vergeleken scores zijn indirecte metingen van de leesbaarheid van teksten. Over de theoretische validiteit (= construct validity) is hiermee nog niet veel gezegd (vgl. paragraaf 6 hierna). De onderwijzersoordelen in Utrecht (Y2) en Breda (Y1) correleren nagenoeg volledig (R = .97). Het overall-clozegemiddelde (Y7) correleert zeer hoog met de Utrechtse en Bredase onderwijzersoordelen over de teksten (een resp. R van .89 en .92), zodat deze drie variabelen onderling vervangbaar zijn. De grote verrassing in deze validatie is wel de empirische validiteit van de formules van Douma en Brouwer. Er zijn immers zwaarwegende bezwaren tegen hun constructie te geven en ook gegeven door Knegtmans in 1971.Ga naar voetnoot13 Op deze teksten blijken hun formules, die onderling .98 correleren, het redelijk goed te doen: een correlatie tussen de .84 en .91 met de onderwijzersoordelen en een correlatie tussen de .77 en .86 met onze gemiddelde clozescores. In de paragraaf ‘discussie’ (6) komen we terug op de bruikbaarheid van de formules van Douma en Brouwer. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 434]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
c. onafhankelijkheidAls we correlatiematrix 2 bekijken (zie bijlage 2), dan zien we dat het beeld van de intercorrelatie (het verband tussen de verklarende variabelen onderling) uit de studie van Van Hauwermeiren nogal afwijkt van hetgeen hier voor andere teksten voor andere lezers wordt gevonden (zie paragraaf 6). Van Hauwermeiren die veel baanbrekend werk verrichtte in het leesbaarheidsonderzoek voldoet bij de toepassing van multiple lineaire regressie geenszins aan de eis van onafhankelijkheid der verklarende variabelen. Bij de presentatie van zijn vier leesbaarheidsformules zijn er twee waarin de factoren ‘lettergrepen per honderd woorden’ en ‘woorden met meer dan drie lettergrepen per honderd woorden’ voorkomen, die getuige zijn intercorrelatiematrix .87 intercorreleren. Beide formules zijn daarom statistisch gezien ondeugdelijk. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
d. reductie van het aantal variabelenBestudering van correlatiematrix 2 laat eveneens zien dat er variabelen zijn die hoog met elkaar correleren, dat wil zeggen die een grote overeenkomst met elkaar hebben. Is de correlatie tussen twee variabelen groter dan .95 dan kan men rustig stellen dat beide variabelen onderling verwisselbaar zijn. Bij lagere correlaties is de verwantschap van groepen variabelen niet direct te zien. Hiervoor staat een speciale wiskundige techniek, de factoranalyse, ter beschikking. Dit is een op lineaire algebra en correlatierekening berustende techniek, waarmee men kan zien of er zich zogenaamde clusters (groepjes) variabelen vormen, die elk staan voor één onderliggende factor. Nadat we op de door ons gehanteerde veertien tekstkenmerken een factoranalyse hadden toegepastGa naar voetnoot14 bleek dat er duidelijk drie groepjes variabelen waren,
Figuur 1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 435]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
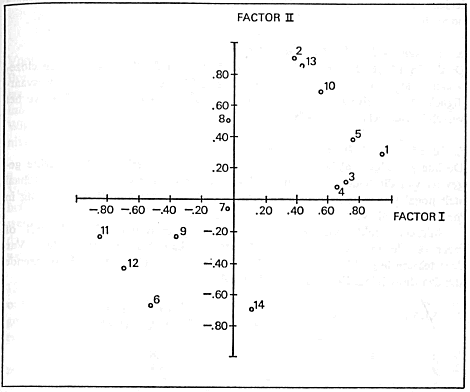 die representant zijn van drie onderliggende factoren. De tabel op blz. 434 en de grafiek op blz. 435 zijn het resultaat van de analyse; zij maken de drie groepen variabelen zichtbaar. Factor I is de onderliggende factor van de variabelen X1 (gemiddelde woordlengte in lettergrepen), X5 (percentage verschillende ‘moeilijke lange woorden’), X3 (percentage substantieven) en X4 (percentage voorzetsels), met als negatieve representanten X11 (percentage éénlettergrepige woorden) en X12 percentage persoonlijke voornaamwoorden). Factor II is de onderliggende factor van de variabelen X2 (gemiddelde T-unitlengte in woorden), X13 (gemiddelde zinslengte in woorden) en X 10 (gemiddelde tanglengte in woorden); X14 (percentage enkelvoudige zinnen) en X6 (percentage persoonsvormen) zijn er de negatieve representanten van. Factor III is de onderliggende factor van de variabelen X9 (percentage tangen) en X8 (percentage bijzinnen). X7 (percentage hulpwerkwoorden) behoort niet tot de factoren I en II en is slechts een zwakke representant van factor III. Het is niet eenvoudig de drie factoren te benoemen, maar de analyse geeft toch een idee van de onderliggende verhouding tussen de door ons gehanteerde tekstkenmerken. Omdat factor III minder dan 10% van de totale variantie verklaart, is het nog niet reëel er een naam aan te geven. Factor I wilden we de | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 436]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
lexicale component en factor II de syntactische component van de leesbaarheid noemen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
e. het leesvaardigheidsniveau per klasOmdat in alle derde, vierde, vijfde en zesde klassen dezelfde verzameling clozetesten is afgenomen, zijn de gemeten gemiddelden een maat voor de leesvaardigheid per jaarniveau. Alle gevonden verschillen bleken significant, behalve het verschil tussen klas 5 en klas 6.Ga naar voetnoot15 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
f. bepaling van de interpretatieschaalDe interpretatieschaal hebben we provisorisch samengesteld uit de beperkte gegevens van dit onderzoek. Een preciese constructie van een interpretatieschaal stelt nogal wat eisen aan de tekstkeuze, zowel voor wat betreft de spreiding in moeilijkheid, als voor het aantal van de te gebruiken teksten. Allereerst stelden we dat een tekst geschikt was voor een klas als 65 % of meer van de onderwijzers van die klas de betrokken tekst geschikt achtte. Van deze teksten bepaalden we de gemiddelde clozescore per klas en de bijbehorende standaardafwijking. Zie onderstaande tabel:
Vervolgens bepaalden we het geschikte gebied (= het niveau waarop teksten met instructiedoeleinden zich dienen te bewegen) door het interval van de hoogste gemiddelde clozescores (zie tabel) tot de laagste gemiddelde clozescores uit te breiden met één maal de standaardafwijking van de betrokken gemiddelden. Dus voor het instructieniveau dienen de clozescores (X1) zich te bevinden in het interval: (40.2 _ 9.7) ⩽ X1 ⩽ (61.6 + 10.8) De scores die buiten dit interval vallen, betekenen òfwel dat de tekst te gemakkelijk is als instructieve tekst (de scores liggen dan op het zogenaamde onafhankelijke niveau), òfwel dat de tekst te moeilijk is als instructieve tekst (de scores liggen dan op het zogenaamde frustratieniveau). In de volgende tabel geven we de drie interpretatieniveau's weer: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 437]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Voor de Angelsaksische literatuur bepaalden Rankin & CulhaneGa naar voetnoot16 evenals eerder BormuthGa naar voetnoot17 de grenzen van de clozescores voor bovenstaande leesniveau's. Alleen wat betreft het derde niveau, het frustratieniveau, komt onze verdeling van de intervallen met Bormuth overeen; het instructieniveau is bij hem veel kleiner. Wij zien voorlopig echter geen reden om van onze bepaling van de interpretatieniveau's af te zien. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
g. predictieVoor de constructie van een betrouwbaar predictief instrument vergrootten we het aantal verklarende variabelen met hun mogelijke interacties. Deze interacties werden gedefinieerd als het produkt van elk paar verklarende variabelen. Op deze wijze kwamen er naast de veertien verklarende variabelen nog een 76 nieuwe variabelen bij. De bewerking van deze gegevens met multiple lineaire regressie (zie noot 12) leverde negentien statistisch betrouwbare formules op. De formules die de ordening van de teksten voor de derde tot en met de zesde klas het best weergeven, hebben respectievelijk multiple correlatiecoëfficiënten van .90, .94, .97 en .99. De in de formules opgenomen interacties (samengestelde variabelen) maken ze wèl theoretisch interessant, maar in de dagelijkse schoolpraktijk zijn deze formules onbruikbaar, omdat het telwerk van de verklarende variabelen nogal wat tijd in beslag neemt. Daarom presenteren wij hier voor elke klas een betrekkelijk eenvoudige en betrouwbare schattingsprocedure voor de geschiktheid van informatieve teksten. Voor klas 3 en 4 maken we hiertoe gebruik van de éénheidsfactorformules met ‘verschillende ‘moeilijke lange woorden’’ (X5). Van de volgende vuistregel kan men dus gebruik maken om oefenteksten te verzamelen voor de les begrijpend lezen in de derde en in de vierde klas: een tekst voor de derde klas mag niet meer dan drie verschillende ‘moeilijke lange woorden’ per honderd bevatten; Worden deze limieten overschreden, dan valt de gemiddelde clozescore in het zogenaamde frustratiegebied: de gemiddelde clozescores van de derde en vierde klassers komen dan boven de 72 % fout te liggen. De hier gepresenteerde vuistregel mag erg simpel lijken, hij berust echter volledig op twee statistisch betrouwbare regressievergelijkingen, waarvoor de hier- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 438]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
voor bepaalde ondergrenswaarde van het frustratiegebied, 72, is ingevuld. X5 is dan de enige onbekende in de vergelijking die bij oplossing repectievelijk de waarden 3,196 en 4,759 oplevert. Voor de vuistregel geldt dus dezelfde statistische betrouwbaarheid als geldt voor de formules. Voor de vuistregel geldt bovendien dat de relatie tussen de afhankelijke variabele (= gemiddelde clozescore) en de verklarende variabele (= percentage verschillende ‘moeilijke lange woorden’) niet omkeerbaar is: de vuistregel mag niet gebruikt worden om teksten leesbaar te maken (vergelijk paragraaf 3). De beide formules waarop de hier gepresenteerde moeilijkheidsschatters berusten, zien er als volgt uit:
(CFi = het gemiddelde percentage fout ingevulde clozeëenheden per tekst) Toepassing van de vuistregel voor derde- en vierdeklasteksten levert, behalve de snelle geschiktheidsuitspraak slechts een relatieve ordening van teksten op. Toepassing van de formule (1) en (2) geeft een betrouwbare indicatie van de absolute moeilijkheid van de teksten, uitgedrukt in percentage fout ingevulde clozeeenheden. Voor de vijfde en zesde klas, waar het leesvaardigheidsniveau op een significant hoger peil is gekomen, kan de moeilijkheid van teksten niet meer met de vuistregel worden geschat. Voor een betrouwbare schatting zullen de verklarende variabelen X5 en X7 moeten worden geteld. Bewerkt men de tellingen met de onderstaande formules, dan verkrijgt men zeer betrouwbare schattingen van de moeilijkheid van informatieve teksten voor klas vijf en zes uitgedrukt in het percentage fout ingevulde clozeëenheden.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
6. Discussiea. theoretische validiteitDe geschetste opzet van het onderzoek geeft een antwoord op de vraag in hoeverre van uit de hier gepresenteerde resultaten gegeneraliseerd kan worden. Noch de keuze van de scholen noch de keuze van de teksten was aselect, zodat voor generalisering van de resultaten naar een welomschreven klasse teksten en naar een welomschreven klasse scholen geen sprake kan zijn. De hiervoor gepresenteerde resultaten hebben een voorlopig karakter: ze gelden zeker voor de gehanteerde steekproeven, en als zodanig kunnen de resultaten beschouwd worden als indicatie voor algemener geldende regels. Dit soort wetmatigheden kan pas kracht van wet krijgen als ze in een uitgebreider design worden aangetoond. Is daarvoor niet de mankracht, noch de tijd, noch het geld aanwezig, dan ligt de enige mogelijkheid van verantwoord onderzoek in het successievelijk onderzoeken van allerlei deelaspecten van het begrijpend lezen op kleine schaal. Hebben we inderdaad gemeten wat we wilden meten? Deze vraag naar de | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 439]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
theoretische validiteit van de ‘leesbaarheid’ zullen we beantwoorden door een vergelijking te maken tussen de beide gebruikte onafhankelijke variabelen, de cloze procedure en het onderwijzersoordeel. Het onderwijzersoordeel, hoe statistisch betrouwbaar ook, is een indirecte meting van het begrip-zoals-bedoeld: het is een schatting van een groep deskundigen over de te verwachten moeilijkheidsgraad van bepaalde teksten voor bepaalde lezers. De lezer zelf, laat staan het proces dat zich binnen de lezer afspeelt, komt er in deze meting helemaal niet aan te pas. De clozeprocedure daarentegen betrekt de lezer zelf bij de schatting van de moeilijkheid van bepaalde tekstpassages, maar ook de clozeprocedure is een operationalisering van wat bedoeld is te meten. Het percentage fout ingevulde open plaatsen in een systematisch verminkte tekst wordt aangenomen als een betrouwbare schatting van de moeilijkheid van die tekst. Wie dat doet, gaat ervan uit dat er een causaal verband bestaat tussen begrip van de tekst en het percentage fout ingevulde clozeëenheden. Nu zijn er wel allerlei empirische validiteitsbepalingen op de resultaten van de clozeprocedure gepleegd, die alle de zojuist gegeven causaliteitsonderstelling lijken te bevestigen, althans er niet mee in tegenspraak lijken te zijn, maar al deze validaties zijn van hetzelfde theoretische niveau. Geen van de operationalisaties meet begrip-van-een-tekst-zoals-bedoeld met zekerheid, omdat er geen aanvaarde theorie van het begrijpend lezen voorhanden is. Er zijn weliswaar, algemeen erkende, deelvaardigheden aan het proces van het begrijpend lezen onderscheiden, maar tot nu toe is men er nog niet in geslaagd het bestaan van meer dan twee ervan empirisch aan te tonen: ‘word knowledge’ en een groep van drie andere vaardigheden die zo hoog intercorreleerden dat aangenomen mag worden dat ze slechts één onderliggende basisvaardigheid meten.Ga naar voetnoot18 Deze vaardigheid is zoiets als: het verband kunnen leggen tussen elementen in grotere delen dan een zin. Er is dus geen aanvaarde theorie en zelfs het bestaan van bekende leesvaardigheden moet worden betwijfeld. Blijft over de vraag naar het verband tussen de clozeprocedure enerzijds en begripsvragen of begripstesten anderzijds. Uit het voorgaande mag worden afgeleid dat ook voor begriptesten elke theoretische fundering ontbreekt. Elke set vragen bij een tekst is een nieuwe operationalisering van het begrip-zoals-bedoeld en wat de validiteit betreft minstens zo gebrekkig; wat de betrouwbaarheid betreft, loopt men met vragen een veel grotere kans op een geringe betrouwbaarheid omdat het construeren van vragen een moeilijke en hoog gekwalificeerde opgave is. De beoordeling van de antwoorden op vragen is een bijkomende moeilijkheid, die bij zogenaamde open vragen veel groter is dan bij zogenaamde meerkeuzevragen. Al met al geldt voor een willekeurige set vragen bij een tekst, of het nu open of gesloten vragen zijn, dat de theoretische validiteit ervan moet worden vastgesteld. Daarom is het in het leesonderzoek aan te bevelen met meer dan één criterium voor begrip, of voor moeilijkheidsgraad of voor leesvaardigheid te werken, omdat elke operationalisering empirisch steun kan geven aan een door de onderzoeker in eerste instantie gekozen criterium. De clozeprocedure | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 440]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
en het onderwijzersoordeel zijn dus weliswaar indirecte metingen van de moeilijkheidsgraad van teksten, maar de clozeprocedure doet het zeer betrouwbaar en het onderwijzersoordeel bevestigt de waarde die er op het eerste gezicht lijkt te bestaan. De betrouwbaarheid van twee andere criteria die veel toepassing hebben gevonden in Nederland, de formules van Douma en Brouwer, is om nog andere redenen aanvechtbaar. Zoals we in paragraaf 5c aan de formules van Van Hauwermeiren illustreerden, geldt ook hier een hoge intercorrelatie tussen de verklarende variabelen (We maten een R van .61 tussen de gemiddelde woord- en zinslengte). Voor de door ons geselecteerde instructieve teksten geldt dus dat de factoren gemiddelde woord- en zinslengte elkaar beïnvloeden. De eis van onafhankelijkheid wordt hier overtreden, zodat een formule met genoemde factoren statistisch onbetrouwbaar is. De formules van Douma en Brouwer mogen dus niet gebruikt worden voor de schatting van de leesbaarheid van instructieve teksten van de basisschool, op grond van een te grote afhankelijkheid van de factoren gemiddelde woord- en zinslengte in dat soort teksten. Hiertegenover staat het argument dat de beide formules in de praktijk blijken te werken op onze teksten: ze correleren -.82 (Douma) en -.84 (Brouwer) met de overall clozescore. Daarnaast is de intercorrelatie in het corpus teksten van Van Hauwermeiren tussen de gemiddelde woord- en zinslengte -.17: Voor deze teksten kan de statistische onbetrouwbaarheid niet tégen Douma en Brouwer worden aangevoerd. Blijven echter nog de bezwaren van Knegtmans tegen de constructie, die niet met behulp van multiple regressie tot stand kwam. Het is op grond van bovengenoemde waarneming niet eenvoudig een duidelijk standpunt in deze kwestie in te nemen. Wij adviseren voorlopig (zolang er niet meer empirische gegevens bekend zijn) op teksten voor de basisschool onze formule toe te passen en de formules van Brouwer en Douma te gebruiken voor moeilijke teksten. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
b. de onderwijzersoordelenDe inventarisatie van de criteria die de Utrechtse onderwijzers zeiden te gebruiken bij het beoordelen van teksten op geschiktheid voor hun leerlingen, leverde een indrukwekkende lijst tekstkenmerken op. De analyse laat zien dat slechts één kenmerk statisch significant is. De variantie van hun oordeel blijkt namelijk voor 86% verklaard te worden door de gemiddelde zinslengte. De overige gekwantificeerde tekstkenmerken dragen aan deze variantie niets meer bij. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
c. de leesvaardigheidZoals wij in paragraaf 5e zagen, bleek de leesvaardigheid van de vijfde naar de zesde klas niet meer significant toe te nemen. Dit lijkt de indruk te bevestigen dat de zesde klas een herhaling is van de vijfde, tenminste voor wat betreft begrijpend lezen. Wij vragen ons af of dit een wenselijke toestand is, en zo nee, of | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 441]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
er iets aan deze stagnatie van het leerproces kan worden gedaan. Wij denken hier aan de implementatie van de cursus begrijpend lezen, die in het kader van het SVO-project 0-275 wordt ontwikkeld.Ga naar voetnoot19 Wij vragen ons bovendien af of de leesvaardigheid na de zesde klas wel weer toeneemt, en hoe dat precies gebeurt in elk van de naar schooltype onderscheiden brugklassoorten. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
d. de tangconstructiesDe factor tangconstructies zoals die door Van Hauwermeiren werden geoperationaliseerd leek aanvankelijk goede resultaten op te zullen leveren. Uit correlatiematrix 2 blijkt dat onze operationalisaties X9 en X10 met Y7 respectievelijk -.48 en .80 correleren. Dit betekent dat beide variabelen wel een rol spelen, maar in de regressieanalyse onvoldoende van de variantie bleken te verklaren op ons tekstmateriaal. Het loont naar ons idee zeker de moeite op moeilijker materiaal met beide variabelen verder te experimenteren.
Instituut De Vooys, Emmalaan 29, Utrecht. f. zondervan p. van steen g. gunneweg | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Geraadpleegde litteratuur
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 442]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 443]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bijlage 1
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Het lezen van een correlatiematrixHet lezen van een correlatiematrix is te vergelijken met het lezen van een ‘competitiepool’ van een willekeurige sport. Horizontaal en vertikaal zijn de met elkaar te ‘polen’ elementen in dezelfde volgorde geplaatst. In ons geval kan dus het verband tussen welke twee variabelen van de negen dan ook, worden afgelezen. In de bovenstaande matrix hebben we het verband tussen Y5 en Y6, de mate van overeenstemming tussen de gemiddelde clozescores van klas 5 en 6, omcirkeld: R = .97. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 444]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bijlage 2
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 445]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bijlage 3WoordenlijstDeze woordenlijst bevat 35 woorden van meer dan drie lettergrepen, ‘moeilijke lange woorden’, welke frequent voorkomen in het geschreven Nederlands. Bij berekening van factor X5 werden die woorden van meer dan drie lettergrepen geteld die niet op deze lijst voorkomen. Deze lijst werd samengesteld met behulp van de woordfrequentielijst van A.G. Sangers.Ga naar voetnoot20
|
|