
De Nieuwe Taalgids. Jaargang 80
(1987)– [tijdschrift] Nieuwe Taalgids, De–
[pagina 251]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Letter- en woordfrequenties in Nederlandse krantentekstM.P.R. van den Broecke, M. Elstrodt en A. Aerts0 SamenvattingWegens de ontoereikendheid van bestaande studies over woordfrequenties in het Nederlands worden hieronder de resultaten van een nieuwe telling van ongeveer l½ miljoen woorden uit krantenteksten gepresenteerd. Uit de resultaten de telling bleek dat een dergelijk corpus ongeveer 50.000 verschillende woordvormen omvat. Er worden tevens letterfrequenties gerapporteerd. Uit de frequentieverdeling van woorden, geordend naar lengte, zijn gegevens over de syllabestruktuur van het Nederlands af te leiden. Uit vergelijkingen met andere tellingen bleek tenslotte dat de frequentieverdeling van woorden uit krantenteksten anders is dan van woorden die uit andere bronnen afkomstig zijn. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1 InleidingOver de gebruiksfrequenties van Nederlandse woorden en woorddelen zoals letters zijn tot nu toe relatief weinig gegevens beschikbaar. De eerste poging tot het vaststellen van de gebruiksfrequenties van Nederlandse woorden werd gedaan door De la CourtGa naar voetnoot1 in 1937. Hij baseerde zich op een door hemzelf uitgekozen corpus van 1 miljoen woorden uit populaire literatuur en kinderboeken. LinschotenGa naar voetnoot2 heeft de resultaten van deze telling in 1965 verder geanalyseerd. De 102 frequentste woorden, die 49% van het corpus omvatten, werden niet afzonderlijk geteld maar tot hoogfrequent bestempeld. Het corpus bestaat niet in computer-leesbare vorm, en verbuigingen en vervoegingen werden eerst getransformeerd naar hun lemma-vorm. Een tweede tellingGa naar voetnoot3 stamt uit 1965 en werd verricht door Van Berckel, Brandt Corstius, Mokken en Van Wijngaarden. Hier werden ongeveer 50.000 woorden krantentekst geteld uit 10 kranten die verschenen op 19 juni 1956. Woorden werden gecodeerd op woordsoort. Dit corpus is klein, en gegeven de zeer tijdsgebonden bron, niet erg representatief. De meest recente telling werd verricht door Uit den BoogaartGa naar voetnoot4 in 1975. Dit corpus bestaat uit 600.000 woorden afkomstig uit zes verschillende schriftelijke bronnen, en bovendien uit 120.000 woorden die werden opgetekend uit spontane conversaties. De frequentie van elke woordvorm, frequenties van de lemmata waarvan ze werden afgeleid, en woordsoort wordt gespecificeerd voor elk der 7 subcorpo | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 252]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ra. Dit corpus is in computer-leesbare vorm beschikbaar, zij het dat dit bestand vrij veel fouten bevat. Ieder die wel eens met dit corpus gewerkt heeft zal hebben ontdekt dat ook dit corpus relatief klein is, en intuïtief frequente woorden zoals ‘spraak’ er niet voorkomen. Toepassingen van gebruiksfrequentie gegevens zijn te vinden op tal van gebieden zoals spraakaudiometrie, woordherkenning, quantificering van linguïstische verwachtingspatronen, automatische spellingscorrectie etc. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2 MethodeOp grond van bovenstaande gegevens werd besloten een nieuwe frequentietelling voor het Nederlands te verrichten op basis van krantentekst. Om representativiteit binnen de gekozen tekstsoort te bereiken diende de telling zich over een ruime tijdsperiode uit te strekken, en redelijk groot van omvang te zijn. Derhalve werd een telling begonnen van alle woorden in redactionele teksten van een regionaal dagblad, nl. De Haarlemse Courant, in een tempo van ongeveer 20.000 woorden per.dag. Dit verslag beschrijft een aantal karakteristieken van een aldus verzameld corpus (ULEX. FREQ) van ongeveer 1,5 miljoen woorden, geteld in het eind van 1985 over een periode van ongeveer 4 maanden. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3 ResultatenHet bleek dat de 1.452.030 getelde woordvormen (tokens) gespreid waren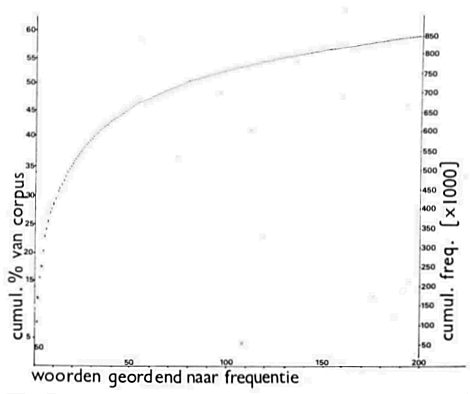 Figuur 1.
Relatie tussen de hoogfrequente 200 woorden in het corpus en de hoeveelheid woordvormen uit de tekst die daarmee worden omvat, uitgedrukt als cumulatief percentage en in absolute cumulatieve frequentie. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 253]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
over 53.244 verschillende woorden (types). De relatie tussen type en token wordt getoond in figuur 1 voor de 200 frequentste woorden (die in bijlage 1 worden genoemd met hun absolute frequenties).
Figuur 1 toont de cumulatieve frequentie, uitgedrukt in absolute getallen en als percentage van het totale corpus. Uit de figuur blijkt dat de eerste 10 woorden reeds 27% van het corpus omvatten, de eerste 50 woorden 45%, de eerste 100 woorden 52%, en de eerste 200 59%. De letterfrequenties zoals aangetroffen in het corpus worden gegeven in tabel I in absolute getallen en percentages.
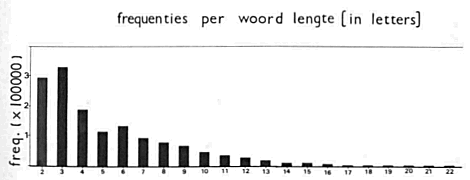 Figuur 2.
Verdeling van woorden met woordlengte van 2 t/m 22 letters in absolute frequentie van voorkomen in het corpus. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 254]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4 DiscussieOm de hier verkregen resultaten te vergelijken met de eerder genoemde gebruiksfrequentie tellingen van Van Berckel e.a. en Uit den Boogaart is gebruik gemaakt van Pearson's produkt-moment correlatie, die niet alleen rangordes maar ook de absolute frequenties in acht neemt. Voor het Uit den Boogaart corpus werd zowel de totale telling van alle geschreven bronnen (600.000 woorden) als het subcorpus krantentekst bekeken. Hoewel dit de eis schendt die Pearson's toets stelt, nl. dat de te correleren gegevens onafhankelijk dienen te zijn, geeft het enig inzicht in de vraag in hoeverre gebruiksfrequenties van woorden uit krantenteksten andere kenmerken hebben dan frequenties uit andere schriftelijke bronnen. Aangezien ons corpus geen woordsoortcodering kent, zijn identieke woorden uit verschillende woordklassen zoals die in de andere twee corpora voorkomen samgengevoegd. Tabel II bevat de correlaties en bijbehorende t-waarden van de 10, 50 en 200 frequentste woorden uit elk corpus. Alle verkregen correlatiewaarden zijn zeer significant (p <.0001).
De hoogste correlatiewaarden treffen we aan tussen het ULEX.FREQ corpus en het Uit den Boogaart subcorpus krantentekst (UN), de daarna hoogste waarde tussen van Berckel e.a. (B) en UN, en de daarna hoogste waarde tussen ULEX. FREQ en B. Dit wijst erop, dat de tekstbron een faktor van betekenis is wanneer corpora worden vergeleken. Gebruiksfrequenties van woorden uit diverse krantenteksten vertonen een verband dat sterker is dan wanneer ze met teksten uit | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 255]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
andere bronnen worden vergeleken. Hoe groter het corpus, ook al worden slechts de meest hoogfrequente woorden vergeleken, hoe duidelijker het verband. De gebruiksfrequenties van woorden in krantenteksten vertonen dus karakteristieken die ze onderscheiden van andere tekstbronnen, en die karakteristieken worden duidelijker naarmate de omvang van het corpus toeneemt. De letterfrequenties zoals gegeven in tabel I vertonen uitstekende overeenstemming met die uit Van Berckel e.a. (Pearson's r = 0,994 t = 45,3 df=25 p <.001). Aangezien deze twee corpora een faktor 30 in omvang verschillen mogen we veilig aannemen dat de frequentieverdeling van letters in het Nederlands zeer stabiel is, en relatief onafhankelijk van de grootte van de steekproef. De verdeling van de frequenties over woorden van verschillende letterlengte, vergelijk figuur 2, laat een relatieve piek zien bij woorden van 3 en 6 letters, en een relatief dal bij een woordlengte van 5 letters. Dit is toe te schrijven aan de syllabestructuur van het Nederlands. Bij een woordlengte van 5 letters vindt er statistisch gesproken een overgang plaats van monosyllabische naar bisyllabische woorden. Een vergelijkbaar dal, hoewel minder uitgesproken, wordt ook gerapporteerd in Van Berckel e.a. Verder laat figuur 2 aflopende frequenties bij oplopende woordlengte zien, een verschijnsel dat reeds in 1935 door ZipfGa naar voetnoot5 als universeel taalkenmerk werd gesignaleerd. De telling van krantentekst ten behoeve van het corpus ULEX.FREQ loopt inmiddels door, waarbij gestreefd wordt naar een uiteindelijke grootte van 20 miljoen woorden, waarmee het een der grootste corpora op dit gebied zal zijn.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 256]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|