
Tabu. Jaargang 16
(1986)– [tijdschrift] Tabu–
[pagina 351]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Implicationele ordening in de beheersing en verwerving van een regiolectGa naar eind*
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1. Theoretisch kader1.1. Algemene TaalververvingstheorieTegenwoordig is de hypothese-theorie de aanvaarde taaiverwervingstheorie. Deze theorie houdt in, dat taalverwerving een proces is, waarbij het kind op grond van het taalaanbod uit zijn omgeving hypotheses opstelt met betrekking tot juist en vooral effectief taalgebruik. Deze hypotheses worden bijgesteld of verworpen, wanneer dit na toetsing noodzakelijk blijkt. De theorie gaat er van uit, dat kinderen eerst heel algemene hypotheses opstellen, die vooral gericht zijn op functioneel taalgebruik. Als belangrijkste ondersteuning voor deze theorie worden doorgaans de overgeneralisaties aangevoerd, die alle kinderen gedurende het leerproces maken. Hypotheses worden in eerste instantie bijgesteld om tot een beter verlopende communicatie te komen. Zo wordt het grammaticale systeem langzamerhand genuanceerd. Uitgaande van de hypothese-theorie kan men zich afvragen met behulp waarvan kinderen hypotheses opstellen. Als overgeneralisaties steeds weer optreden bij taalverwerving, zoals tot dusver uit onderzoek gebleken is, dan wijst dit feit in de richting van universele leerstrategieën. De man achter onderzoek naar dergelijke strategieën is Slobin (1973). De strategieën die door hem zijn afgeleid staan bekend als de operatie-principes van Slobin. De volgende operatie-principes zijn voor het onderhavige onderzoek van belang: Operatie-principe A: Kinderen besteden vooral aandacht aan woordeinden. Operatie-principe F: Vermijd uitzonderingen. Universale F1: De volgende stadia in linguïstische markering van een semantisch begrip worden doorgaans waargenomen: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 352]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Universale F2: Regels die van toepassing zijn op grotere klassen worden ontwikkeld voor regels die betrekking hebben op onderdelen van die klassen, en algemene regels worden eerder verworven dan regels voor speciale gevallen. Operatie-principe G: Het gebruik van grammaticale markeringen moet semantisch zinnig zijn. (Slobin 1973: 205, 206) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.2. De verwerving van het genusNaar de verwerving van het genus is nog niet veel onderzoek gedaan. Taalverwervingstheorieën zijn tamelijk semantisch en functioneel geaard. Taal is voor het kind in de eerste plaats een communicatiemiddel. Structurele kenmerken van een taal worden geleerd, omdat ze in dit licht functioneel zijn. Het genus is niet functioneel, althans niet in een taal, waarin zinsvolgorde een grote rol speelt. Schaerlaekens (1980) geeft de verwervingsvolgorde van het lidwoord bij een vijftal Nederlandssprekende kleuters:
Schaerlakens gebruikt semantische gronden om te verklaren waarom het onderscheid tussen de en het pas laat blijkt te komen (1980: 172). Zij sluit daarmee aan bij Slobins operatie-principe G, dat inhoudt dat het gebruik van grammaticale markeringen semantisch zinnig moet zijn. Helaas beperkt zij zich bij het geven van de verwervingsvolgorde tot het eerste verschijnen van het en zegt ze niets over volledige en juiste differentiatie tussen de en het. Extra (1978) besteedt aandacht aan de beheersing van het bepaalde lidwoord, het demonstrativum en de vorming van het adjectief. Het meest frequent komen fouten voor, die een overgeneralisatie van masc./fem.-kenmerken inhouden. Dit kan ons inziens verklaard worden met behulp van operatie-principe F van Slobin: Vermijd uitzonderingen. Extra constateert verder voor de Nederlandstalige groep de volgende beheersingsvolgorde:
Een mogelijke verklaring voor de beste beheersing van de adjectiefvorming (wel of geen toevoeging van de verbuigings-/e/) zien we in operatie-principe A van Slobin (1973: 191), dat inhoudt dat kinderen vooral aandacht aan woordeinden besteden. Als verklaring voor het verschil in beheersing van het bepaalde lidwoord enerzijds en het demonstrativum anderzijds zou de aanbodsfrequentie genoemd kunnen worden. (Extra 1978: 141) Toch leren kinderen, die uitsluitend Nederlands spreken, op den duur het grammaticale geslacht van substantieven. Uit onderzoek (Van Oosterhout 1985) is gebleken, dat Nederlandssprekende kinderen aan het eind van hun basisschooltijd vrijwel geen moeilijkheden meer hebben met het onderscheid tussen de- en hetsubstantieven. Klaarblijkelijk stellen ze op grond van het taalaanbod, dat bestaat uit het correcte gebruik van het genusonderscheid door de ouders, hypotheses op, die ze bijstellen zolang ze daartoe aanleiding zien. Ze maken zo een eigen systeem voor toekenning van het grammaticale geslacht, dat in hun ogen | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 353]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
enige (semantische) zin heeft. Het lijkt aannemelijk, dat de semantische features [animate] en [human] daarbij een rol spelen. Deze features functioneren ook in het volwassenen-systeem, bijvoorbeeld bij pronominalisatie (het meisje, zij). Bovendien worden deze features al vroeg verworven. Clark (1973) heeft aangetoond, dat de eerste semantische features waarvan kinderen gebruik maken, afgeleid zijn van hun waarnemingen (bijvoorbeeld vorm, grootte, geluid). Daarbij horen ook features als [animate] en [human]. Zij veronderstelt vervolgens, dat kinderen in een later stadium, wanneer ze meer weten over de structuur van hun taal, leren welke van de van de waarneming afgeleide features in die taal functioneel zijn. Het is echter nog niet duidelijk hoe bepaalde features een speciale status krijgen. In het taalaanbod waar Groningssprekende kinderen op het Hogeland tijdens hun taalverwerving mee geconfronteerd worden, is geen sprake van een duidelijk genusonderscheid. Uit eerder onderzoek (Wierenga 1984) bleek, dat het genusonderscheid door de generaties heen vertroebeld werd door de afwezigheid van het bepaalde lidwoord de in het oorspronkelijke dialect en de slechte verstaanbaarheid van het proclitische lidwoord t. Bovendien trekt het semantische kenmerk [animate] van substantieven altijd de masc./fem. relativa aan. Als gevolg hiervan hanteren de ouders van de huidige jongste generatie een één-genussysteem. In de overige varianten van het Gronings is het bepaalde lidwoord de wel aanwezig, maar substantieven met het semantische kenmerk [+menselijk] hebben een masc./fem. relativum bij zich. Waarschijnlijk zal de verwerving van het genus bij Groningssprekende kinderen uit deze gebieden op nagenoeg dezelfde wijze verlopen als bij Nederlandssprekende kinderen, echter met dien verstande, dat er langer sprake zal zijn van overgeneralisaties van mas./fem. kenmerken waar het het relativum betreft. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1.3. Het verwerven van een tweede taalWanneer in huiselijke kring altijd dialect gesproken wordt, zal het kind tegenwoordig in een andere omgeving al vrij snel met een geheel ander taalaanbod geconfronteerd worden. Twee taalsystemen moeten dus als communicatiemiddel dienen voordat één van beide systemen in grote lijnen beheerst wordt. Daarnaast zijn de taalsystemen voor het kind niet meer duidelijk te onderscheiden op grond van de situatie waarin ze gebruikt worden; de standaardtaal is niet meer de taal die alleen op school gesproken wordt. Het bovenstaande is met name van toepassing op de informanten die aan ons onderzoek hebben deelgenomen. De eerste taal van deze kinderen is een vorm van het Gronings, maar van hen wordt echter verwacht, dat ze al vrij snel een tweede taal beheersen, namelijk de standaardtaal. Voor de informanten van het Hogeland geldt dat zij, zodra zij met het Nederlands in aanraking komen, ontdekken dat er een onderscheid bestaat tussen de- en het-woorden, dat zij niet herkennen in het taalgebruik van hun ouders. Hierdoor ontstaat het gevaar van interferentie, dat in het algemeen echter ook door de tweetalige zelf ingezien zal worden. Ben Zeev (1977) constateert vier kenmerken van tweetalige kinderen:
Deze vier kenmerken zijn gericht op systeemscheiding en dus op voorkoming van | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 354]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
interferentie. Toch blijft interferentie bestaan; dit resulteert volgens Ben Zeev in convergentie van de beide taalsystemen. Dat wil zeggen, dat er een simplificatie van regels tussen de twee talen optreedt. Overgeneralisatie en simplificatie van regels zullen een taal als resultaat hebben, die wij in een eerder stadium tussentaal hebben genoemd (Oosterhof, Wierenga en Van Zantwijk 1982). Een uitgebreide theoretische uiteenzetting met betrekking tot tussentaal (of interlanguage) is te vinden in Corder (1976). Bij Corder heeft de term ‘interlanguage’ echter vooral betrekking op een vorm van de tweede taal van kinderen of volwassenen, terwijl wij onder tussentaal eveneens een geëvolueerde vorm van de eerste taal verstaan. Met zijn taaltheorie sluit Corder aan bij de hypothesetheorie in het algemeen: een tweedetaalleerder stelt een hypothetische, persoonlijke grammatica op, die hij zowel produktief als receptief toetst. Hij stelt de grammatica bij zolang hij daartoe gemotiveerd wordt, bijvoorbeeld doordat hij niet goed begrepen wordt. Zodra de motivatie wegvalt, treedt er een proces in werking, dat Corder fossilisatie noemt (1976: 22). Dat wil zeggen dat een bepaald stadium in de tussentaal door de spreker als eindpunt van de ontwikkeling aanvaard wordt. Dit stadium hoeft natuurlijk niet samen te vallen met de streeftaal. Samengevat zullen Groningssprekende kinderen in eerste instantie op basis van het semantische kenmerk [animate] hypotheses opstellen ten aanzien van variabelen, die samenhangen met het genus. Als gevolg hiervan zullen ze de masc./fem.- kenmerken gaan overgeneraliseren. Vervolgens treedt er een nuancering van het systeem op, waarbij een onderscheid wordt gemaakt tussen de- en het-woorden. Deze nuancering zal het eerst optreden bij 1) de informanten afkomstig uit een gebied waar dit onderscheid in het taalgebruik voor de volwassenen duidelijk aanwezig is, 2) het adjectief, vervolgens bij het lidwoord en daarna bij het demonstrativum (cf. Extra 1978) en uiteindelijk ook bij het relativum. De verwerving van het Nederlandse genussysteem zal dan volgens de theorie van Ben Zeev (1977) op de volgende manieren kunnen verlopen:
Gezien het feit dat we te maken hebben met twee taalystemen die heel dicht bij elkaar liggen, kunnen we ook verwachten dat er interferentie optreedt waardoor convergentie van beide taalsystemen plaatsvindt. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. Opzet van het onderzoekHet onderzoek bestond uit een mondelinge test die op systematische wijze het gebruik van het genus ontlokte. De test richtte zich op vier variabelen waarbij het onderscheid tussen neutr.- en masc./fem.-woorden een rol speelt: het adjectief na onbep. lidwoord, het bep. lidwoord, het demonstrativum en het relativum, en is opgebouwd rond veertig zelfstandige naamwoorden, verdeeld over de categorieën de [-animate], de [+animate], het [-animate] en het [+animate]. In totaal hebben 74 informanten deze test zowel in het Gronings als in het Nederlands afgelegd. Hun gemiddelde leeftijd was 14 jaar. De informanten waren afkomstig uit vier verschillende dialectgebieden van Groningen: het Hogeland, het Zuidelijk Westerkwartier, de Veenkoloniën en het Oldambt. De test voor het Gronings is afgenomen door een Groningssprekende en de test voor het Nederlands door een uitsluitend Nederlandssprekende interviewer. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 355]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. De verwerking van de gegevens3.1. De implicationele schaalDe veronderstelling is, dat toekennen van het juiste genus eerder wordt aangetroffen bij het [-animate]-woorden dan bij het [+animate]-woorden. Echter, nuancering bij het [+animate]-woorden impliceert nuancering bij het [-animate]-woorden. Dit principe kan worden geïllustreerd aan het adjectief. Hier onderscheiden we drie lecten naar hun mate van nuancering.
Het onderscheid tussen mooi en mooie is bij de [+/-animate]-woorden (zoals de plant) niet aanwezig: elk der drie typen sprekers zegt een mooie plant. Het uitsluitend voorkomen van deze drie typen sprekers betekent dat een vierde combinatie, (een mooi paard, een mooie hemd), slechts bij uitzondering wordt aangetroffen. Juist het niet voorkomen van deze combinatie betekent dat we de drie typen kunnen ordenen. Het gebruik van een mooie hemd impliceert dat de spreker ook zal zeggen een mooie paard, en het gebruik van een mooi paard impliceert dat de spreker ook zal zeggen een mooi hemd. De ordening van de drie lecten, A1, A2, A3, wordt ook wel een implicationele schaal genoemd. Een lect A1-spreker gebruikt ongenuanceerde taal, een lect A3-spreker gebruikt genuanceerde taal, en een lect A2-spreker neemt een tussenpositie in. De kwaliteit van een implicationele schaal voor de nuancering van het [-animate]-woorden en het [+animate]-woorden kan worden geëvalueerd met behulp van het probabilistisch cumulatieve schaalmodel van Mokken (1971) (cf. Van Hout e.a. 1985 voor een enigszins verouderd alternatief). Deze procedure kan eenvoudig worden uitgelegd aan de hand van een kruistabel, waarin de frequenties van de vier logische mogelijkheden tussen nuanceringen in het adjectief bij het [-animate]-en het [+animate]-woorden voorkomen.
Het [-animate] en het [+animate] noemen we variabelen, en in termen van genuanceerdheid noemen we een mooi hemd en een mooi paard het positief alternatief van deze variabelen. Van de 100 sprekers in dit voorbeeld zeggen 30 een mooi paard en 60 een mooi hemd. In termen van genuanceerdheid noemen we de variabele het [+animate] moeilijker dan het [-animate]. Voor een implicationele schaal geldt, dat een spreker die het positief alternatief geeft voor de moeilijke variabele, ook het positief alternatief zal geven voor de gemakkelijke variabele. Dat betekent dat in de kruistabel de cel een mooi paard, een mooie hemd een frequentie 0 zal hebben. Deze cel wordt dan ook wel de foutencel genoemd. In de praktijk zullen er veelal wel enige mensen zijn die, in tegenstelling tot de verwachting van een implicationele schaal, toch zowel een mooi paard als een mooie hemd zeggen. Dit geobserveerde aantal (0) wordt nu vergeleken met een verwacht aantal (E) onder de hypothese dat beide variabelen statistisch onafhankelijk zijn. Per cel staan deze verwachte aantallen tussen haakjes aangegeven. Ze zijn eenvoudig te berekenen als het produkt van de rij- en kolom-marginalen, | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 356]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
gedeeld door het totaal aantal informanten. De kwaliteit van een implicationele schaal wordt nu gegeven door Loevingers homogeniteitscoëfficiënt H: H=1 - O/E Als vuistregel geldt dat twee variabelen pas een implicationele schaal vormen wanneer H > 0.30. Een implicationele schaal tussen meer dan twee variabelen kan worden geëvalueerd door alle n(n-1)/2 kruistabellen te maken, en per kruistabel de waarden 0 en E te vinden. Loevingers H voor de gehele implicationele schaal wordt nu berekend door de som van alle frequenties 0 over alle kruistabellen (0 : tweemaal het aantal waargenomen fouten voor de schaal als geheel) te vergelijken met de som van alle frequenties E over alle kruistabellen (E : tweemaal het aantal verwachte fouten voor de schaal als geheel). Bovendien kan nu voor elke variabele afzonderlijk een homogeniteitswaarde worden berekend. Hiertoe worden 0 en E gevonden als de som van alle (waargenomen en verwachte) fouten in die kruistabellen, waarin de variabele een rol speelt. Een verzameling variabelen vormt een implicationele schaal wanneer: 1) voor elke kruistabel geldt dat 0 > E; 2) elke variabele een H(i)-waarde heeft groter dan 0.30; 3) de homogeniteitswaarde voor de schaal als geheel ook groter is dan 0.30. Er is nog een aantal aanvullende criteria voor de evaluatie van een tweetal variabelen als een implicationele schaal die we hier niet zullen behandelen (zie hiervoor Niemoller, Van Schuur en Stokman 1980). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3.2. Een implicationele schaal voor de vier variabelenIn de praktijk bepalen we tot welk type een informant behoort niet op basis van een enkele taaluiting, maar op basis van een tiental uitingen, zodat we kunnen nagaan hoe consistent de informant de taaluitingen van een bepaald type reproduceert. Immers, een informant zou in tien taaluitingen wel vier maal een mooie paard en zes maal een mooi paard kunnen zeggen. Echter, van iedereen kon het type worden vastgesteld zonder al te veel intra-individuele inconsistenties waar te nemen. Zoals we informanten kunnen indelen naar de mate waarin ze overgeneraliseren bij het adjectief, kunnen we dezelfde informanten ook indelen naar de mate waarin ze overgeneraliseren bij het bepaald lidwoord, het demonstrativum en het relativum.
Opgemerkt zij weer dat alle typen sprekers de [+/-animate]-woorden op dezelfde wijze gebruiken: de plant, bij het bepaalde lidwoord, die plant bij het demonstrativum en een plant, die... bij het relativum. Hier speelt het feature [animate] geen rol. Binnen elk van deze vier variabelen (adjectief, bepaald lidwoord, demonstrati- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 357]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
vum en relativum) kunnen dus gradaties worden aangebracht in mate van overgeneralisatie. Maar in hoeverre zijn de gradaties volgens deze vier variabelen met elkaar te vergelijken? Geven ze in essentie dezelfde informatie, zodat drie van de vier variabelen overbodig zijn bij de bepaling van de mate van overgeneralisatie van een informant? Of hebben alle vier variabelen niets met elkaar te maken, en onderscheiden ze de informanten naar verschillende variabelen die niet over één kam geschoren mogen worden? Indien dit laatste het geval zou zijn, dan bestaat er kennelijk dus niet zoiets algemeens als overgeneralisatie tout court, maar zullen we bij overgeneralisatie altijd moeten specificeren over welke variabele we het hebben. Wanneer we verschillende groepen informanten van elkaar willen onderscheiden naar overgeneralisatie zou deze laatste uitkomst ons welkom zijn, omdat we zo'n onderscheid dan per variabele moeten nagaan. We zullen dus moeten nagaan of deze laatste uitkomst wel of niet optreedt. Er is nog een derde manier, een soort tussenweg, op basis waarvan de vier variabelen onderling gerelateerd kunnen zijn. Dat is dat ze weliswaar gradaties van overgeneralisatie weergeven, maar dat de verschillende typen op basis van de vier variabelen elkaar slechts gedeeltelijk, of misschien wel helemaal niet overlappen. Zo zijn er aanwijzingen dat overgeneralisatie eerder voorkomt bij het relativum dan bij het demonstrativum, eerder bij het demonstrativum dan bij het bepaald lidwoord en eerder bij het bepaald lidwoord dan bij het adjectief. We kunnen dit wellicht als volgt op een rechte lijn voorstellen, die we het continuüm tussen ongenuanceerd en genuanceerd taalgebruik noemen. 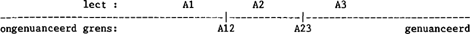 De drie typen op basis van het adjectief zijn te representeren als bepaalde intervallen op een ééndimensioneel continuum. Deze intervallen worden van elkaar gescheiden door de grenzen A12 en A23. Deze grenzen zijn te interpreteren als de grens tussen informanten die zodanig overgeneraliseren dat ze een mooie hemd zeggen, en informanten die zodanig nuanceren dat ze een mooi hemd zeggen (grens A12), en als de grens tussen informanten die op analoge wijze te onderscheiden zijn, omdat ze een mooie paard of een mooi paard zeggen (grens A23). Evenzo kan het continuüm worden opgedeeld op basis van het bepaald lidwoord (met grenzen B12 en B23), het demonstrativum (grenzen D12 en D23) en het relativum (grenzen R12 en R23). Combinatie van alle vier variabelen levert een continuüm op, waarin negen gebieden te onderscheiden zijn: 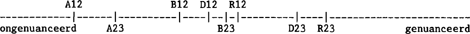 Bij het verwerken van de gegevens zullen we nagaan of de vier variabelen inderdaad beschouwd kunnen worden als gradaties van eenzelfde onderliggend continuüm ongenuanceerd - genuanceerd taalgebruik. Deze hypothese wordt dan geplaatst tegenover de alternatieve hypothese, dat de vier variabelen onderling niets met elkaar te maken hebben. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3.3. De evaluatie van de vier variabelen als een implicationele schaalDe relaties tussen de variabelen zullen we eerst illustreren aan de hand van een perfecte implicationele schaal tussen twee variabelen, zoals bijvoorbeeld het adjectief A en het bepaald lidwoord B. We gaan er hierbij vanuit, dat we weten tot welke combinatie van typen uit A en B (drie maal drie is negen combinaties in totaal) elke informant behoort. Het aantal informanten behorende bij elke combi- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 358]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
natie van typen kan worden weergegeven in een kruistabel, met de gegevens over het adjectief in de rijen en de gegevens over het bepaald lidwoord in de kolommen (zie tabel 2).
Met betrekking tot het adjectief kunnen we nu zeggen dat 20% van de informanten nuanceert in een mate voorbij de grens A23. 60% (de zonet genoemde 20% plus 40%) heeft een mate van nuancering voorbij de grens A12. Met betrekking tot het bepaald lidwoord kunnen we nu zeggen dat 30% van de informanten een mate van nuancering heeft voorbij de grens B23, en dat 80% een nuancering heeft voorbij de grens B12. Van de negen typen informanten op basis van beide variabelen is type A3,B3 het type met de grootste mate van nuancering. Maar welk van de twee typen A2,B3 of A3,B2 is hierna het type met de grootste mate van nuancering? We beantwoorden deze vraag door na te gaan hoeveel personen een bepaalde grens hebben overschreden: wanneer er minder personen zijn die de grens A23 hebben overschreden dan er personen zijn die de grens B23 hebben overschreden, dan noemen we de overgang van A2 naar A3 moeilijker dan de overgang van B2 naar B3. Dit betekent dat het type A2,B3 meer zal overgeneraliseren dan het type A3,B2. In dit concrete voorbeeld had slechts 29% van de informanten de grens A23 gepasseerd, terwijl 30% van de informanten de grens B23 had gepasseerd. In dit voorbeeld is type A2,B3 dus het op één na meest ongenuanceerde type. Het feit dat de grens A23 moeilijker is dan de grens B23 heeft een belangrijke implicatie. Het betekent namelijk dat iemand van het type A3 dus altijd de grens B23 gepasseerd moet hebben, juist omdat dit een gemakkelijker grens is. Dus type A3,B2 mag niet voorkomen! En, sterker nog, type A3,B1 mag dus helemaal niet voorkomen!! Een informant van het type A3 kan worden aangeduid als iemand die op het continuüm ongenuanceerd - genuanceerd taalgebruik al redelijk ver naar de kant van het genuanceerde taalgebruik te representeren is, terwijl de grens tussen de typen B1 en B2 veel dichter in de buurt van het ongenuanceerde taalgebruik ligt. Uit de bespreking van deze tabel vallen de volgende algemene conclusies te trekken. In de eerste plaats kan op basis van het aantal informanten dat beschreven kan worden als type A1, A2 of A3, en het aantal dat beschreven kan worden als type B1, B2 of B3, worden afgeleid welke combinaties van typen verwacht kunnen worden in het geval er sprake is van een perfecte implicationele ordening tussen de variabelen adjectief en bepaald lidwoord. Vijf van de negen cellen in de kruistabel kunnen worden aangewezen als toegestane combinaties van typen en vier cellen kunnen worden aangemerkt als verboden cellen. De verwachte frequentie van de verboden combinaties onder statistische onafhankelijkheid is heel eenvoudig uit te rekenen op analoge wijze als bij de tweebij-twee-kruistabel. Deze staan tussen haakjes aangegeven. De verwachte frequentie van de verboden patronen in een kruistabel is nu de som van de verwachte frequenties van A1,B3; A2,B1; A3,B1 en A3,B2, ofwel: 12 + 8 + 4 + 10 = 34. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 359]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Als criterium voor het beoordelen van het geobserveerde aantal verboden combinaties ten opzichte van het verwachte aantal, kan nu dezelfde homogeniteitscoëfficiënt van Loevinger gebruikt worden, zoals is voorgesteld door Molenaar (1982). We hanteren nu dezelfde vuistregel als in het geval van dichotome variabelen. Ook de uitbreiding naar een implicationele schaal van meer dan twee variabelen verloopt analoog aan het dichotome geval. Dezelfde eisen aan de homogeniteitswaarden van elke variabele afzonderlijk, en aan die van de schaal als geheel (H > 0.30) gelden ook hier. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3.4. Het vergelijken van informantenWanneer blijkt dat de onderzochte variabelen een implicationele schaal vormen, dan kunnen we de informanten indelen naar hun positie op de schaal. Bij een perfecte implicationele schaal kan aan de hand van de antwoorden van een informant exact worden opgemaakt tussen welke grenzen op het continuüm hij/zij gepresenteerd kan worden. De plaats van een informant op het continuüm kan dan bijvoorbeeld worden weergegeven met het aantal grenzen dat hij heeft gepasseerd. Dit aantal is gelijk aan de som van het aantal grenzen dat hij/zij per variabele heeft gepasseerd. Een informant die de grens A12 heeft gepasseerd (lect A2 of lect A3) krijgt hiervoor 1 punt; een persoon die ook de grens A23 heeft gepasseerd (lect A3) krijgt voor de variabele adjectief 2 punten. Voor 4 variabelen zijn 8 grenzen te passeren, hetgeen betekent dat er 9 mogelijke waarden zijn, welke liggen tussen 0 (geen enkele grens gepasseerd, volledig ongenuanceerd) en 9 (alle grenzen gepasseerd, volledig genuanceerd). Deze somscore is òok te vinden uit de som van de type-aanduiding van de informant over alle variabelen min het aantal variabelen. Strikt genomen is de zo gevonden schaalwaarde voor een informant een rangnummer op een ordinale schaal. Voor het vergelijken van groepen informanten zullen we evenwel aannemen, dat deze scores te interpreteren zijn op een intervalschaal, zodat vergelijkingen tussen groepen met eenvoudige statistische modellen, zoals t-toetsen of variantie-analyses, mogelijk worden. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4. Resultaten en conclusiesTen eerste blijkt er zowel voor het Gronings als voor het Nederlands een implicationele ordening te bestaan tussen de categorieën het [-animate] en het [+animate] (H = .84 voor het Gronings en H = .80 voor het Nederlands). Dat wil zeggen dat wanneer er nuancering van het systeem optreedt, dit inderdaad het eerste plaatsvindt bij de het [-animate]-substantieven. Toch blijven in het Nederlands en het Gronings overgeneralisaties veelvuldig voorkomen (+/-50%). Verder onderzoek zal aan moeten tonen of het genussysteem na het veertiende levensjaar nog (verder) genuanceerd wordt of dat er hier sprake is van fossilisatie. Dat laatste is niet onaannemelijk, gezien het feit dat voor een adequate communicatie het genusonderscheid niet van belang is. Bovendien blijkt, dat de meeste informanten geen systeemscheidende strategieën toepassen, waardoor het Gronings en het Nederlands voor een aantal variabelen convergeren. Dit wordt geïllustreerd door het feit, dat de meeste informanten het Groningse genussysteem in dezelfde mate nuanceren of overgeneraliseren als het Nederlandse. Wanneer er simplificatie van regels optreedt, gebeurt dat in beide taalsystemen op dezelfde wijze. Hieruit kunnen we afleiden, dat er geen sprake is van maximalisatie en van neutralisatie van verschillen tussen het Gronings en het Nederlands. Dit alles wordt bijvoorbeeld geïllustreerd door de uitingen van informant 7:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 360]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ten tweede is er voor het Nederlands sprake van een implicationele ordening tussen de variabelen A=adjectief, B=bep. lidwoord, D=demonstrativum en R=relativum (zie tabel 3).
Voor elke variabele geldt, dat H(I) groter is dan .30. De H voor de schaal als geheel is eveneens groter dan .30. Voor het Gronings ziet de ordening er als volgt uit:
Ook hier zijn alle H(I)-waarden en de H-waarde voor de schaal als geheel groter dan .30. Deze schalen representeren de beheersingsvolgordes. De volgorde is voor het Gronings en het Nederlands dezelfde.Ga naar eind2. Het adjectief wordt dus het beste beheerst, vervolgens het bepaald lidwoord etc. Deze beheersingsvolgorde komt overeen met de volgorde, die Extra (1978) constateerde bij jonge Nederlandstalige kinderen. Wanneer we ervan uitgaan, dat de beheersingsvolgorde een afspiegeling is van de verwervingsvolgorde, dan kunnen we stellen, dat de Groningssprekende kinderen het Nederlandse genussysteem op dezelfde wijze verwerven als Nederlandssprekende kinderen. Het is niet precies duidelijk waarom het demonstrativum en het relativum samen op de laatste plaats staan (in dit geval wil dat zeggen dat beide variabelen even slecht worden beheerst). Gezien het voorafgaande zou men verwachten dat het relativum op de laatste plaats zou staan. Het zou kunnen zijn dat de op latere leeftijd verworven regel voor het relativum toegepast wordt op het eerder verworven demonstrativum. De vormen van deze woordsoorten zijn immers identiek (vergelijk het Nederlands: dat boek, dat op tafel ligt). Wanneer we de vier groepen met behulp van t-toetsen met elkaar vergelijken, dan blijkt dat groep 4 (bestaande uit informanten, die afkomstig zijn uit de Veenkoloniën) voor het Gronings een significant hogere gemiddelde somscore heeft dan de overige groepen (P < .02). Dit betekent, dat informanten afkomstig uit een gebied waar het genusonderscheid in het taalgebruik van de volwassenen duidelijk aanwezig is, een genuanceerder genussysteem hanteren dan hun leeftijdgenoten uit andere dialectgebieden, zoals reeds is verondersteld (zie 1.3). De groepen 2 (Westerkwartier) en 3 (Oldambt) scoren echter niet significant hoger dan groep 1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 361]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(Hogeland), (P > .10). Klaarblijkelijk zijn de bepaalde lidwoorden e en d' geen duidelijke genusmarkeerders en hebben scholieren uit het Westerkwartier en het Oldambt evenveel moeite met de verwerving van het genussysteem als die van het Hogeland. Bovenstaande verschillen treffen we niet allemaal aan in de Nederlandse gegevens. Groep 4 scoort weer significant hoger dan de groepen 1 en 2 (P < .05), maar niet hoger dan groep 3 (P > .25). Groep 3 scoort bovendien significant hoger dan groep 2 (P < .02). Vooralsnog is er geen verklaring voor het feit, dat informanten, afkomstig uit het Oldambt, een genuanceerder genussysteem gebruiken. Het is echter duidelijk, dat bijna alle informanten een aantal variabelen op veertienjarige leeftijd (nog) niet goed beheersen. In termen van het continuümmodel betekent dit, dat er informanten zijn die zich aan het begin van of halverwege het continuüm ongenuanceerd-genuanceerd bevinden (+/- 60% van de informanten bevindt zich nog links van de grens B12, en heeft dus alleen het adjectief volledig verworven). Het tijdstip waarop het genussysteem volledig beheerst wordt, is aanzienlijk later dan bij Nederlandssprekende kinderen. Men kan zich zelfs afvragen, of het systeem nog wel volledig verworven zal worden. Ga naar eind1. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 362]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Literatuur
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||