
Tabu. Jaargang 20
(1990)– [tijdschrift] Tabu–
[pagina 84]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
Toepassingen van lexicale databanken binnen het psycholinguistisch onderzoek naar lexicale verwerking
| ||||||||||||||||||||||||||||||||||||||||||||||||||
2 Kernproblemen van de lexicale verwerkingOnze opmerkelijke vaardigheid in het begrijpen van gesproken taal danken we in belangrijke mate aan de efficiëntie en de snelheid waarmee we woorden in ons mentale lexicon kunnen opzoeken. Dankzij ons lexicale verwerkingssysteem zijn we bij het vertalen van zintuiglijke ervaringen in betekenisvolle interpretaties in staat vormen te relateren aan betekenissen. Ter beschrijving van dit verwerkingssysteem nemen psycholinguïsten aan dat we beschikken over een centrale opslagplaats of mentaal lexicon, dat dient om verschillende soorten (fonologische en orthografische, maar ook semantische en syntactische) informatie in het lange termijn-geheugen te bewaren. Het moeilijke probleem van de arbitraire afbeelding van de vorm op de betekenis lost het lexicon op door vorm- en betekenisinformatie bij elkaar op te slaan. Binnen dit kader kunnen drie belangrijke probleemgebieden worden onderscheiden:
Het zal duidelijk zijn dat de antwoorden op deze vragen nauw samenhangen. Om een voorbeeld te noemen, de manier waarop een woord herkend wordt, | ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 85]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
hangt af van hoe het is opgeslagen, en andersom. Dit artikel zal met name gaan over het woordherkenningsprobleem, waarbij zaken van lexicale representatie aan de orde komen die voor de herkenning van belang zijn. Meer informatie over het gebruik van lexicale databanken is te vinden in Pols (1987) en Schreuder en Kerkman (1987). | ||||||||||||||||||||||||||||||||||||||||||||||||||
3 Toepassingen van lexicale databankenIn wat volgt komt de rol aan de orde die LDBs zijn gaan spelen in het onderzoek naar lexicale verwerking. Eerst bespreken we hoe ze gebruikt worden bij de voorbereiding van psychologische experimenten, waarmee psycholinguïsten taalgedragsdata van proefpersonen verzamelen. LDBs zijn van onschatbare waarde voor de selectie van experimentele stimuli, woorden die de proefpersonen in deze experimenten voorgeschoteld krijgen. De tweede belangrijke toepassing die we bespreken betreft verschillende manieren om LDBs statistisch te analyseren om op die manier meer inzicht te krijgen in de structuur en de werking van het lexicon. | ||||||||||||||||||||||||||||||||||||||||||||||||||
3.1 De selectie van talige stimuliHet psycholinguïstisch onderzoek van de laatste twintig jaar heeft een aantal verschillende factoren aan het licht gebracht die de woordherkenning bepalen. Tabel 1 geeft een overzicht van de belangrijkste.
| ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 86]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
Psycholinguïsten moeten al deze verschillende factoren of onafhankelijke variabelen kunnen controleren en manipuleren bij de voorbereiding en uitvoering van hun experimenten. Het zal dan ook geen verbazing wekken dat de selectie van stimuli een bron van aanhoudende zorg voor de psycholinguïst is. Niet voor niets stelde Cutler in de titel van een artikel uit 1980: ‘Het is een verschrikkelijke ellende om materiaal te maken, oftewel: zullen we in 1990 überhaupt nog in staat zijn om psycholinguïstische experimenten uit te voeren?’. Het is nu 1990, en dankzij gecomputeriseerde lexicale databanken kunnen we nog steeds experimenten doen. De meeste relevante eigenschappen van woorden en van het lexicon zijn te vinden in LDBs. Door het stellen van de juiste vragen aan LDBs is de psycholinguïst in staat om voor ieder soort experiment stimuli met de gewenste combinatie van eigenschappen te verzamelen. Meer en meer worden experimentele stimuli niet alleen om hun inherente eigenschappen geselecteerd, maar ook om die van hun concurrenten. De systematische studie van eigenschappen van het lexicon en van lexicale concurrenten vormt een andere belangrijke toepassing van LDBs met een dieper intrinsiek wetenschappelijk belang. | ||||||||||||||||||||||||||||||||||||||||||||||||||
3.2 Lexicale statistiekStatistische analyses van grote lexicale databanken stellen de psycholinguïst in staat de structuur van het lexicon te onderzoeken. De lexicale statistiek kan regelmatigheden in het lexicon en relaties tussen verschillende soorten lexicale informatie aan het licht brengen. Statistische methoden bieden ons bovendien de mogelijkheid om woordherkenningsprocessen te onderzoeken. Zij stellen ons in staat om na te gaan in hoeverre verschillende soorten lexicale informatie onderscheid kunnen maken tussen lexicale ingangen. We kunnen bijvoorbeeld vragen in hoeverre de lengte of de klemtoonpatronen van woorden onderscheid kunnen maken tussen verschillende lexicon-ingangen. In combinatie met bepaalde aannames over lexicale verwerking kunnen deze statistische anlyses dienen als basis voor voorspellingen over het moment en het verloop in de tijd van de woordherkenning. De meest elementaire vorm van lexicale statistiek is het tellen van het aantal databank-ingangen dat een of meer relevante eigenschappen (zoals die uit Tabel 1) bezit. We kunnen bij voorbeeld tellen hoeveel woorden we hebben van bepaalde foneemlengtes, en dan constateren dat dit aantal varieert als een functie van de lengte. De lexicale statistiek kan ook twee of meer eigenschappen van woorden met elkaar in verband brengen, zoals hun lengte en hun frequentie (de wet van Zipf) of hun klinkerklasse (bij voorbeeld voorklinkers) en hun vormklasse (Sereno en Jongman, 1990). Afhankelijk van de manier waarop het lexicon wordt geanalyseerd kunnen we verschillende soorten toepassingen van de lexicale statistiek onderscheiden. Een eerste type lexicale statistiek wordt veel gebruikt bij de automatische | ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 87]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
spraakherkenning. Deze methode behelst het berekenen en vergelijken van het relatief onderscheidend vermogen van een gegeven hoeveelheid informatie of van een bepaald type onderscheiding. Dit geschiedt door het berekenen van de grootte van de equivalentieklassen die ontstaan als het lexicon volgens deze onderscheidingen verdeeld wordt. De leden van een gegeven equivalentieklasse kunnen niet meer van elkaar onderscheiden worden (bij voorbeeld ‘tree’ en ‘sun’ zijn gelijk wat fonemische woordlengte betreft). Als complement voor equivalentieklassen kunnen we gelijkheidsomgevingen (similarity neighborhoods) definiëren die gebaseerd zijn op het ontbreken (absence or loss) van een specifiek type informatie. Volgens de meest gebruikelijke definitie (Landauer en Streeter, 1973) zijn buren woorden die onderling slechts een letter of foneem in een willekeurige positie verschillen. Deze buren zijn ononderscheidbaar zo gauw als deze letter of deze foneeminformatie verloren gaat. Een derde toepassing van de lexicale statistiek ten slotte staat in dienst van een computationeel model, dat het moment voorspelt waarop een woord kan worden herkend; dit zullen we predictieve statistiek noemen. Hieronder gaan we nader in op elk van de drie genoemde toepassingen. | ||||||||||||||||||||||||||||||||||||||||||||||||||
3.2.1 Equivalentieklasse-analysesBinnen de psycholinguïstiek en het onderzoek naar automatische spraakherkenning wordt de informatieve waarde van specifieke onderscheidingen geëvalueerd in termen van de grootte en het lidmaatschap van equivalentieklassen. Hoe kleiner de equivalentieklasse is die door een bepaalde distinctie gegenereerd wordt, des te informatiever wordt deze distinctie geacht te zijn. Verder dient ook rekening gehouden te worden met de mate waarin deze distincties opvallen in het signaal. Daarom is het zinvol om in spraak en in woorden die eigenschappen te selecteren, die voor de luisteraar (of voor de computer) zowel robuust (duidelijk herkenbaar) zijn in het signaal als discriminerend (onderscheidend) met betrekking tot het lexicon. De statistische analyses om equivalentieklassen te karakteriseren zijn in de loop van de tijd steeds verfijnder geworden. Oorspronkelijk werden ruwe maten gehanteerd als aantal equivalentieklassen of gemiddelde klassegrootte, gecombineerd met maximale equivalentieklasse-grootte en percentage woorden dat alleen in een equivalentieklasse voorkomt. Vervolgens werd verwachte equivalentieklasse voorgesteld (Huttenlocher, 1984) als een betere maat, die precieser de feitelijke verdeling van woorden in hun equivalentieklasse weerspiegelt (in plaats van de uniforme verdeling die aangenomen wordt in de gemiddelde equivalentieklasse-groote). Carter (1987) wees op een andere manier om equivalentieklassen te evalueren. In plaats van het berekenen van de reductie van de zoekruimte die bereikt wordt door kritisch onderzoek, is het ook mogelijk om de hoeveelheid werk te berekenen die na deze reductie nog nodig is om te komen tot een unieke bepaling van een gegeven doel- | ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 88]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
woord. Zo verkleint een distinctie die een lexicon van 10.000 woorden verdeelt in tien gelijke equivalentieklassen van elk duizend woorden de zoekruimte met 90 procent. Volgens Carter (1987) en Altman (1990) is dit echter nog niet alles wat erover te zeggen valt. Immers, deze eerste verdeling heeft slechts een kwart van de informatie geëxtraheerd die nodig is om het doelwoord op unieke wijze te identificeren, aangezien daarvoor nog drie soortgelijke opdelingen nodig zijn. Daarom heeft Carter een informatietheoretische maat voorgesteld, het percentage van geëxtraheerde informatie (PIE, percentage of information extracted). In de volgende alinea's hanteren we verschillende maten om analyses van equivalentieklassen voor drie soorten informatie te onderzoeken. | ||||||||||||||||||||||||||||||||||||||||||||||||||
3.2.1.1 RepresentatieniveauIn een aantal studies is nagegaan wat de consequenties zijn van de aanname van verschillende representatieniveaus op de grootte van equivalentieklassen. Shipman en Zue (1982) gaven als eersten lexicaal-statistische gegevens over equivalentieklassen op basis van zes robuuste of brede categorieën van segmenten: klinkers, nasalen, sterke fricatieven, zwakke fricatieven, occlusieven en liquidae. Het woord ‘slim’ zou in dit geval gerepresenteerd worden als de sequentie: sterke fricatief - liquida - klinker - nasaal. Hun bevindingen met betrekking tot de reductie van de zoekruimte op basis van deze categorieën staan in Tabel 2. De naar frequentie gewogen data houden rekening met de frequentie van de individuele woorden. We zien dat deze zesvoudige classificatie resulteert in een aanzienlijke reductie van de zoekruimte.
| ||||||||||||||||||||||||||||||||||||||||||||||||||
3.2.1.2 Beklemtoonde en onbeklemtoonde lettergrepenDe informatieve waarde van beklemtoonde en onbeklemtoonde lettergrepen is in verscheidene lexicaal-statistische studies vergeleken. Huttenlocher (1984) beweerde dat beklemtoonde lettergrepen informatiever zijn dan onbeklemtoonde. Om dit te demonstreren nam hij een robuuste kenmerkclassificatie aan (Shipman en Zue, 1982) en verving hij hetzij de beklemtoonde of de | ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 89]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
onbeklemtoonde lettergreep door een* (een plaatsvervanger zonder informatieve waarde). Hij vond voor beklemtoonde lettergrepen kleinere verwachte equivalentieklassen dan voor onbeklemtoonde. Altman en Carter (1984), die de PIE-methode hanteerden, vonden alleen verschil in informatieve waarde tussen beklemtoonde en onbeklemtoonde lettergrepen voor volledige fonemische beschrijvingen en niet voor de robuuste kenmerk-representaties. Verder ontdekten ze dat de verschillen bij de fonemische representatie voornamelijk toe te schrijven waren aan het feit dat meer klinkertypes kunnen voorkomen in beklemtoonde lettergrepen. Deze verklaring maakt dat de gevonden verschillen in informatieve waarde minder interessant zijn. | ||||||||||||||||||||||||||||||||||||||||||||||||||
3.2.1.3 Woordbegin en woordeindeDe meeste modellen voor woordherkenning benadrukken het belang van het woordbegin (bij voorbeeld Marslen-Wilson en Welsh, 1978). Om te bepalen of de speciale status van het woordbegin toegeschreven moet worden aan het simpele feit dat het als eerste door de hoorder waargenomen wordt, of dat het werkelijk meer informatie bevat dan andere woorddelen, is het noodzakelijk om de informatieve waarde van begin en eind met elkaar te vergelijken. Voor het Nederlands is dit gedaan door de aantallen lettergreeptypen die in woordbegin en woordeinde aangetroffen worden met elkaar te vergelijken (Van Heuven en Hagman, 1988). De analyse wees uit dat de inventaris van lettergrepen die aan het begin van woorden voorkomen rijker is (2865) dan die aan het eind (1715) (beklemtoonde en onbeklemtoonde lettergrepen werden hierbij apart geteld). Pisoni, Nusbaum, Luce en Slowiaczek (1985) voerden een soortgelijke analyse uit, waarbij de mate waarin de eerste helft van het woord de zoekruimte verkleinde vergeleken werd met de reductie door de achterste helft. Ze vonden iets kleinere equivalentieklassen voor de eerste helft (1,7 woorden per klasse versus 1,9). Beide resultaten wekken de suggestie dat het woordbegin belangrijker is dan het woordeinde, maar de invloed van affixen op deze bevindingen moet nog onderzocht worden. | ||||||||||||||||||||||||||||||||||||||||||||||||||
3.2.2 De analyse van lexicale omgevingenGelijkheidsomgevingen worden doorgaans op twee verschillende manieren gekarakteriseerd: dichtheid van de omgeving - het aantal buren - en omgevingsfrequentie - de frequentie van alle buren. Wij (Frauenfelder, Hellwig, Peeters, Marslen-Wilson en Schreuder, 1990) hebben onlangs een analyse uitgevoerd waarin de frequentie van een woord gerelateerd werd aan zijn omgeving, zoals dat ook in eerder onderzoek van Landauer en Streeter (1973) gebeurd was. Onze analyse van omgevingen ging over twee talen (het Engels en het Nederlands), twee modaliteiten (orthografische en fonologische vor- | ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 90]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
men), diverse woordlengtes (van drie tot zes), en acht frequentieklassen. Buren werden gedefinieerd als woorden die een enkele letter, op welke plaats dan ook, verschillen van het doelwoord (zo zijn ‘fun’, ‘sin’, en ‘sum’ alledrie buren van ‘sun’). De analyse van de Engelse en Nederlandse fonologische en orthografische omgevingen werd uitgevoerd op doelwoorden uit alle mogelijke frequentieklassen. In de figuur staan de resultaten van deze omgevingsanalyse voor Engelse doelwoorden met een foneemlengte vier. 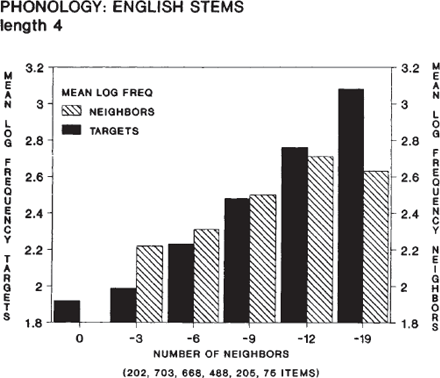 De logaritme van de gemiddelde frequentie van Engelse vier-foneemwoorden en van hun buren als functie van de dichtheid van de omgeving van het doelwoord. Figuur 1
De figuur vertoont een regelmatig patroon dat verbazend constant blijkt bij Engelse orthografische en fonologische doelwoorden. Naar mate de dichtheid van een lexicale omgeving toeneemt, neemt ook de frequentie van de doelwoorden toe alsook die van de buren die de omgeving vormen. Dit distributionele patroon van woorden in hun omgeving werd niet alleen voor andere woordlengtes gevonden, waardoor eerdere resultaten van Landauer en | ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 91]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
Streeter (1973) bevestigd werden in een grotere steekproef van Engelse woorden, maar ook voor Nederlandse fonologische en orthografische vormen voor dezelfde woordlengtes. Het bestaan van vergelijkbare distributionele patronen voor woorden in twee verschillende talen roept een aantal interessante vragen op. Met name moeten we ons afvragen waarom talen het toestaan of zelfs prefereren dat frequentere woorden dichtere gebieden van de lexicale ruimte bezetten, ondanks de mogelijk grotere kans op verwarring bij deze woorden. Bieden de samenstellende fonemen of structuren in deze dichtbevolkte regionen misschien een of ander perceptueel of zelfs produktief voordeel aan de woorden die hier opgeslagen worden? Een tweede onopgelost probleem behelst de preciese invloed van de buren op de herkenning van een woord. Hoe wordt de herkenning van een woord beïnvloed door het aantal en de buren en hun frequentie? Het vinden van antwoorden op deze vragen is momenteel een belangrijk doel van het onderzoek naar lexicale verwerking. | ||||||||||||||||||||||||||||||||||||||||||||||||||
3.2.3 Voorspellende lexicale statistiekLexicaal-statistische resultaten kunnen direkt gebruikt worden om voorspellingen te doen over de woordherkenningsprocessen die spelen bij de woordherkenning, meer speciaal over het verloop in de tijd daarvan. Het Cohort-model bijvoorbeeld (Marslen-Wilson en Welsh, 1978) voorspelt op grond van statistische lexicale analyse het preciese moment waarop een willekeurig gesproken woord in een gegeven lexicon herkend kan worden. Dit herkenningspunt wordt geacht samen te vallen met het uniciteitspunt, dat is het moment waarop het woord uniek wordt ten opzichte van de andere woorden in het lexicon. Zo zou het woord ‘elephant’ geïdentificeerd worden bij de klank /f/ want er zijn geen andere woorden in het lexicon die hetzelfde beginstuk ‘elef’ hebben. Empirisch onderzoek (bijvoorbeeld Marslen-Wilson, 1984; Radeau en Morais, 1990) heeft uitgewezen dat het uniciteitspunt, ondanks de eenvoudige onderliggende aannames, heel behoorlijke voorspellingen doet over woordherkenningsgedrag. Het is ook van belang om voor alle woorden in het lexicon te bepalen waar zich, gemiddeld, het uniciteitspunt bevindt. Marslen-Wilson (1984) berekende het (rekenkundig) gemiddelde aantal woorden in alle cohorten in een Amerikaans-Engels woordenboek van 20.000 woorden. Cohorten bestaan uit die woordgroepen die met een bepaalde hoeveelheid fonetische informatie overeenstemmen. De resultaten lieten een dramatische afname in de gemiddelde cohortgrootte zien: 500 woorden per cohort bij het eerste foneem, 34 bij het tweede, 4,9 bij het derde en 1,9 bij het vierde. Analyses voor het Nederlands (Van Heuven en Hagman, 1988) lieten zien dat het gemiddelde uniciteitspunt zonder klemtooninformatie bij 6,9 foneem lag en een foneem eerder als er wel rekening gehouden werd met de klemtoon. Vergelijkbare resultaten werden bereikt door Carlson, Elenius, Granstrøm en Hunnicut | ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 92]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
(1985) in hun grootschalige analyse van vijf talen (Zweeds, Engels, Duits, Italiaans en Frans). Luce (1986) voerde een statistische analyse uit van een Amerikaans-Engels woordenboek van 20.000 woorden met het doel te bepalen hoevaak woorden niet uniek en dus volgens het cohortmodel niet herkenbaar waren voor hun slotklank. Hij vond dat wanneer er rekening gehouden werd met de woordfrequentie, 38 procent van alle woorden in zijn lexicale databank niet uniek was bij het woordeinde. Uiteraard was dit vooral het geval bij kortere woorden, woorden die vaak ook ingebed in langere woorden voorkomen: 94% van de woorden van twee fonemen, 74% van de woorden van 3 fonemen en 35,6% van de woorden bestaande uit 4 fonemen worden pas uniek na hun einde. Frauenfelder en Peeters (1990) breidden de analyse van Luce uit tot woorden die elders in langere woorden waren ingebed en vonden ongeveer dezelfde mate van lexicale inbedding in initiële, mediale en finale posities. Marcus en Frauenfelder (1985) onderzochten weer een andere gerelateerde maat, namelijk de minimale afwijking, die zij definieerden als de mate van verschil tussen een doelwoord en zijn naaste buur in het lexicon. Deze maat vooronderstelt geen sequentiële vergelijking, zodat ‘nobility’ minimaal verschilt van ‘mobility’, hoewel het verschil in de eerste klank zit. Computeranalyse van een groot fonetisch woordenboek wees uit dat de minimale afwijking na het uniciteitspunt doorgaans gestaag toeneemt met de invoer van extra stimulusmateriaal. Onderzoek naar het vermogen van de verschillende lexicale maten om woordherkenningsgedrag te voorspellen zijn hier natuurlijk cruciaal, net zo goed als de ontwikkeling van nieuwe lexicale maten. | ||||||||||||||||||||||||||||||||||||||||||||||||||
4 ConclusieIn dit artikel hebben we het gebruik geïllustreerd van verschillende LDB-toepassingen in het psycholinguïstisch onderzoek naar spraak- en woordherkenning. Eerst werd aangetoond dat LDBs onmisbaar zijn bij het selecteren van experimenteel stimulusmateriaal met de gewenste combinatie van eigenschappen. Veel van deze eigenschappen, zoals het uniciteitspunt, zijn lexicaal-statistisch gedefinieerd. LDBs zoals CELEX beschikken tegenwoordig over een psycholinguïstische trukendoos die veel van deze belangrijke maten voor alle lexicale ingangen kan berekenen. Meer ontwikkelingen in deze richtingen staan voor de deur. Verder zal ook andere voor de psycholinguïstiek relevante informatie in LDBs worden opgenomen, zoals een score voor de bekendheid, woordassociaties en overgangswaarschijnlijkheden tussen woorden. Ten slotte mogen we verwachten dat er bij elk woord in de databank een of meer gedigitaliseerde uitspraakvoorkomens zullen worden opgenomen. Dit klankmateriaal zal te zijner tijd ook in psycholinguïstische experimenten kunnen worden gebruikt. De statistische analyse van de lexicale databank is de tweede belangrijke | ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 93]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
toepassing die we besproken hebben. We hebben verschillende soorten lexicale statistiek onderscheiden, die elk op hun eigen wijze inzicht bieden in de lexicale verwerking en de lexicale representatie. Uiteindelijk mag men hopen dat het mogelijk wordt om deze inzichten te formaliseren in termen van een heel ander type lexicale databank, dat veel nauwer aansluit bij wat we van onze experimenten en uit de lexicale statistiek geleerd hebben. Deze databank, of liever dit computationele model, kan door de simulatie van lexicale processen een belangrijke rol gaan spelen bij de vermeerdering van onze kennis van deze processen. | ||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
| ||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 94]
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||