
Tabu. Jaargang 35
(2006)– [tijdschrift] Tabu–
[pagina 119]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Enquêteonderzoek naar modale uitdrukkingen in Nederland en België:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1. InleidingIn de loop van ons onderzoek naar uitdrukkingsmiddelen van modaliteit in het Nederlands zijn een aantal mogelijke verschillen tussen Belgisch-Nederlands (vanaf hier: BN) en Nederlands-Nederlands (NN) naar boven gekomen.Ga naar eind1 Sommige verschillen waren al in de literatuur aan bod gekomen (bv. Van der Wouden 1998), maar veel andere waren nog niet eerder opgemerkt. We wilden empirisch nagaan in welke mate het inderdaad gaat om significante verschillen tussen BN en NN. Dat hebben we op twee manieren gedaan: met corpusonderzoek en een aanvullend enquêteonderzoek. Eerst lichten we kort ons corpusonderzoek toe. In de rest van dit artikel gaan we wat dieper in op het enquêteonderzoek, de problemen waarmee we bij het uitwerken van de methode werden geconfronteerd en hoe we die hebben pogen op te lossen. We besluiten het artikel met de bespreking van enkele resultaten. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 120]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. CorpusonderzoekDe Nederlandse taal heeft verschillende middelen ter beschikking om de werkelijkheid te modificeren of te evalueren. Wij hebben het gebruik van modale werkwoorden onderzocht (moeten, mogen, kunnen e.d.), modale constructies met adverbia (misschien, zeker, vast, beter, best, liefst e.d.) en de modale infinitiefconstructie (als in het is te betalen). Onze eerste toetsing van potentiële verschillen in het gebruik van uitdrukkingen van modaliteit geschiedde in het Corpus Gesproken Nederlands (CGN).Ga naar eind2 Om de vergelijking tussen BN en NN te maken, hebben we het corpusmateriaal ingedeeld in een BN en een NN subcorpus,Ga naar eind3 waarin we zoekopdrachten hebben uitgevoerd met het programma Corex. Het zoekresultaat werd rechtstreeks verwerkt of het werd geval per geval doorgenomen als dat nodig was. Bij een te groot zoekresultaat hebben we ons op een willekeurige steekproef gebaseerd. De verwerking gebeurde volgens verschillende vergelijkingsmethodes, die toegelicht zijn in Diepeveen e.a. (2006). Met een chikwadraattoets werd ten slotte bepaald of het gebruik van een modale uitdrukking in het BN subcorpus significant verschilt van dat in het NN subcorpus. Het corpusonderzoek leidde in de meeste gevallen tot bevestiging van de verwachtingen: voor heel wat mogelijke verschillen tussen BN en NN vonden we evidentie in het CGN, en bovendien bleek een groot aantal van die verschillen ook statistisch significant te zijn (p<0,05). Voor enkele verschijnselen liet het CGN geen significant verschil zien tussen BN en NN. Voor bepaalde verschijnselen leverde corpusanalyse helaas geen resultaat op. Dat moet dan letterlijk genomen worden: het onderzochte verschijnsel kwam niet of nauwelijks voor in het CGN, of het bleek moeilijk opzoekbaar. Zo had het corpusonderzoek uitgewezen dat moeten in combinatie met niet voor een complementaire betekenis een gebruikswijze is die typisch BN is: in NN wordt daarvoor niet hoeven gebruikt (je moet me niet helpen tegenover je hoeft me niet te helpen). Daarom vermoedden we dat ook met andere negatieve of restrictieve elementen, zoals maar, in BN vaker moeten gebruikt zou worden dan hoeven (ik moet maar roepen en hij komt tegenover ik hoef maar te roepen en hij komt). Inspectie van het CGN leverde echter weinig relevante gevallen op. Een te kleine frequentie laat uiteraard geen valabele conclusies toe. Omdat we toch een antwoord wilden op de vragen die het corpusonderzoek niet had beantwoord, hebben we deze kwesties in een enquête verwerkt. Zo hebben we een enquête-vraag opgesteld met restrictief maar, waarin de ene antwoord-mogelijkheid moeten is, en de andere hoeven (zie sectie 4). De enquête wijst uit dat BN-sprekers in deze omgeving eerder moeten kiezen en NN-sprekers hoeven. De aanvullende enquête kan dan een algemenere geldigheid verlenen aan de bevinding uit het corpusonderzoek dat het gebruik van moeten in een negatieve context typisch BN is. In de volgende sectie zullen we de aanvullende enquête als onderzoeksinstrument nader toelichten. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 121]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. Enquêteonderzoek: methode en problemenSchriftelijke groepsenquêteEen schriftelijke groepsenquête leek ons het geschikte instrument om aanvullende data te leveren. Aan die keuze lagen vooral praktische overwegingen ten grondslag. Met een schriftelijke enquête kunnen op systematische wijze gegevens verzameld worden van een grote groep mensen in een tamelijk uitgestrekt gebied. Dat kan bovendien gebeuren in een relatief korte (afname)tijd en met vrij weinig medewerkers en middelen. Die voordelen gelden des te meer bij een groepsenquête waar de aanwezigen onder begeleiding van een enquêteur individueel een vragenlijst invullen. Een vragenlijst met goed voorgestructureerde vragen en antwoordmogelijkheden levert direct de gezochte informatie op, die objectief en relatief probleemloos verwerkt kan worden. Een belangrijk methodologisch voordeel van de schriftelijke groepsenquête is de hoge mate van standaardisering. Alle respondenten krijgen dezelfde stimuli in de vorm van een gedrukte lijst met identieke instructies en een gelijke vraagstelling. De kans op interviewer bias blijft beperkt doordat alle aanwezigen in de groep dezelfde mondelinge introductie krijgen van de enquêteur. Een schriftelijke groepsenquête heeft, zoals iedere andere methode, ook nadelen. Elke testsituatie is kunstmatig. We kunnen niet controleren wat precies de antwoordkeuze van de respondenten heeft bepaald. Met andere woorden, we weten niet of respondenten eerlijk antwoorden, noch of ze een antwoord geven dat overeenkomt met hun feitelijk taalgebruik, vrij van invloed door hun kennis van taalnormen. Hier gaan we dadelijk dieper op in. Evenmin hebben we de mogelijkheid om respondenten bij te sturen of aanvullende vragen te stellen over hun geografische en sociale achtergrond. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
RespondentenWe verwachten dat de voorkeur van respondenten voor bepaalde modale uitdrukkingen beïnvloed wordt doordat iemand NN dan wel BN spreekt. Het land van herkomst van respondenten is dus van belang, maar ook de regio van herkomst binnen Nederland of België kan een rol spelen (zie verderop). Een belangrijk praktisch probleem was dat we wegens de beschikbare tijd beperkt waren in de typen respondenten die konden worden geraadpleegd. Het was niet haalbaar om respondenten uit alle lagen van de populatie te raadplegen. Onze steekproef bestaat uitsluitend uit studenten die toevallig aanwezig waren in colleges van vooraf geselecteerde opleidingen. In totaal hebben we meer dan 900 studenten geraadpleegd. Aan de beperking tot een selecte groep taalgebruikers als respondenten zijn wel methodologische voordelen verbonden. Aan een college neemt altijd een groep deel zodat er geen respondenten op straat of per post gerekruteerd hoefden | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 122]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
te worden met het risico van weigering of non-respons. De groep aanwezige studenten is een willekeurige selectie van (doorgaans) mannen én vrouwenGa naar eind4 van vrijwel dezelfde leeftijd en ongeveer gelijk opleidingsniveau. Zo blijven er automatisch een aantal sociale determinanten van taalvariatie constant: sekse, leeftijd en opleiding. Voor aanvullende informatie moesten de deelnemers wel nog enkele persoonlijke gegevens op het formulier invullen: hun geslacht en geboortejaar, hun moedertaal en waar ze naar school zijn geweest (zie verderop). De ingevulde persoonlijke gegevens vormden een criterium om te bepalen of een respondent al dan niet geschikt was voor het onderzoek. Zo zijn er uitsluitend respondenten geselecteerd met Nederlands als eerste taal, omdat zij het best de nuances zouden kunnen aanvoelen die zo typisch zijn voor uitdrukkingen van modaliteit. Deelnemers die buiten de door ons afgebakende leeftijdsgroepGa naar eind5 vielen of respondenten die hun schooltijd in het buitenland situeerden, werden niet geselecteerd. We zijn ervan uitgegaan dat studenten talig van een vergelijkbaar niveau zijn: in hun opleiding hebben ze intensief contact met hedendaags bovenregionaal taalgebruik. Dat is van belang omdat de focus van ons onderzoek ligt op het voorkomen van veertien modale verschijnselen in het bovenregionale taalgebruik in Nederland en Nederlandstalig België. We moesten er wel rekening mee houden dat modale verschijnselen beperkt kunnen zijn tot één regio. Het zou onterecht zijn om zo'n regionaal verschijnsel veralgemenend BN of NN te noemen. Daarom werd niet alleen rekening gehouden met de factor land (België versus. Nederland), maar ook met de meer specifieke regionale achtergrond van de respondenten. We hebben zes regio's gedefinieerd, om praktische redenen op basis van provinciegrenzen.Ga naar eind6 Kaart 1 laat de regio's zien. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 123]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
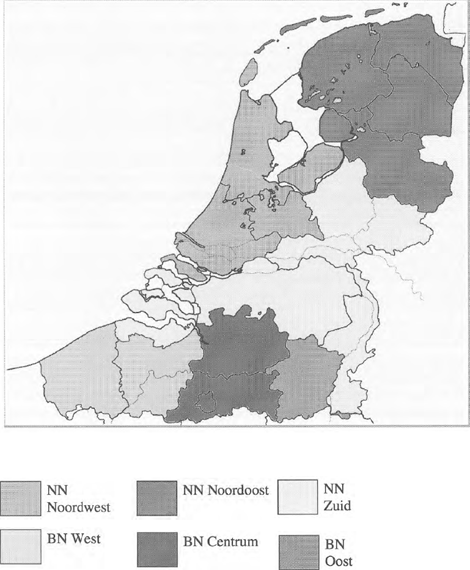
Kaart 1. De zes Nederlandstalige regio's in België en Nederland
Om een representatieve steekproef van BN-sprekers en NN-sprekers te verkrijgen, met een maximale geografische spreiding, hebben we in elke regio respondenten gezocht, en wel op de locaties vermeld in Tabel 1. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 124]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De respondenten werden geselecteerd volgens hun regio van herkomst. Hoewel we universiteiten gekozen hadden die naar onze verwachting vooral studenten uit de eigen regio aantrekken, konden we er uiteraard niet van uitgaan dat de studenten die we daar enquêteerden ook steeds uit de desbetreffende regio afkomstig waren. We hebben dan ook de juiste regio van herkomst bepaald op basis van de plaats waar de respondenten naar de lagere school zijn geweest, wat ze moesten invullen op het enquêteformulier.Ga naar eind7 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
VoorkeurtestDe enquêtevragen volgden het principe van een voorkeurtest (Gerritsen 1991: 18): de respondenten werd gevraagd uit twee zinnen die zin te kiezen die in een gegeven spreeksituatie hun persoonlijke voorkeur heeft (d.w.z. die ze zelf zouden gebruiken). In de cursieve tekst wordt de situatie geschetst, met daaronder de twee keuzemogelijkheden:
De respondenten waren er natuurlijk niet van op de hoogte dat de ene keuzemogelijkheid de neutrale modale uitdrukking bevat, die naar onze verwachting algemeen is voor het hele Nederlandse taalgebied (lusten in het voorbeeld), en dat in de andere zin de vermoedelijk gemarkeerde modale uitdrukking staat, die in de literatuur of door onszelf typisch gevonden wordt voor één nationale taalvariëteit (meestal BN, zoals in het voorbeeld hierboven, BN mogen). De volgorde van het neutrale en het gemarkeerde antwoord hebben we afgewisseld om een vast patroon te vermijden. Elk verschijnsel hebben we getest met twee verschillende enquêtevragen, om een betrouwbaarder meetinstrument te hebben. De semantische en/of syntactische context is telkens lichtjes verschillend. Als we namelijk in beide vragen dezelfde context houden, valt het niet uit te sluiten dat de context het antwoord uitlokt. Zo was (2) de variant van (1): | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 125]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Om volgorde-effecten te voorkomen hebben we verschillende versies van de vragenlijsten verspreid waarin de vragen anders geordend waren. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Twee antwoordmogelijkhedenDat er maar twee antwoordmogelijkheden zijn, kan door respondenten als te beperkend ervaren worden, zoals wanneer de uitdrukking die zij zouden gebruiken niet vermeld is, of als ze antwoordzinnen anders zouden structureren, dan wel een bepaald woord niet kennen of gebruiken. Om de respondenten de mogelijkheid te geven hun antwoord enigszins te nuanceren, hebben we aan het eind van de vragenlijst ruimte voorzien waar ze commentaar konden noteren. Bij de verwerking van de antwoorden hebben vraagspecifieke opmerkingen van de respondent steeds de doorslag gegeven. Bij de voorbereiding van de vragenlijst hebben we overwogen om een aparte instructie in te bouwen voor het geval respondenten geen van beide zinnen bruikbaar zouden vinden, maar uiteindelijk is besloten dat niet te doen. Bij de afnames hebben er maar een paar deelnemers naar gevraagd, en dan kon de enquêteur hen verzoeken toelichting te geven in de commentaarruimte. Wel bestond de mogelijkheid om beide antwoordmogelijkheden aan te kruisen, als de respondent echt niet kon kiezen omdat hij/zij beide zinnen even bruikbaar vond. Een ander probleem dat we hier kort willen noemen, is dat de antwoorden van de respondenten ons niets leren over het relatieve gebruik van de bevraagde uitdrukkingsparen. Als respondenten mogelijkheid A aankruisen, mogen we er niet uit afleiden dat ze de uitdrukking van B nooit gebruiken. En zelfs als alle NN-sprekers antwoord A aankruisen, houdt dat niet automatisch in dat B nooit gebruikt wordt in NN. De enquête verschaft dus geen absolute gegevens, maar een indicatie. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Betrouwbaarheid van de antwoorden. NorminterferentieEen voorkeurtest is geschikter om naar het reële taalgebruik van respondenten te vragen dan een evaluatietest waarin respondenten uitdrukkingen moeten beoordelen in termen van aanvaardbaarheid. Men kan uitdrukkingen volstrekt aanvaardbaar vinden zonder ze zelf ooit te gebruiken, en omgekeerd impliceert het gebruik van een uitdrukking niet per se haar aanvaardbaarheid (cf. Cornips & Poletto 2005: 944). Een belangrijk probleem bij de voorkeurtest blijft evenwel de betrouwbaarheid van de antwoorden die respondenten geven. We veronderstellen dat alle respondenten over het metatalig vermogen beschikken hun eigen | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 126]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
taalgebruik te kunnen beoordelen, maar of ze dat ook echt kunnen, is niet zeker (cf. Deygers e.a. 2002: 38). Modaliteit is bovendien een zeer complexe materie. Een voorkeurtest biedt niet de garantie dat het antwoord van respondenten overeenkomt met hun reële taalgebruik: we riskeren ‘valse voorkeuren’. De grootste uitlokker van ‘valse voorkeur’ is normbesef van de standaardtaal: respondenten die zich bij het antwoorden laten leiden door ‘explicit, prescriptive knowledge about the superordinate variety’ (Cornips & Poletto 2005: 944). Het feit dat onze enquêtevragen binair zijn (er is een keus tussen niet meer dan twee antwoordmogelijkheden) zou tot norminterferentie kunnen leiden. Het zou namelijk de respondenten het idee kunnen geven dat het gaat om een onderscheid tussen ‘goed’ en ‘fout’, dan wel dat de ene antwoord-mogelijkheid ‘beter’ of ‘normaler’ is dan de andere. Om dat effect te voorkomen, hebben we in de mondelinge instructies sterk benadrukt dat ons onderzoek geen kwestie is van ‘goed’ of ‘fout’. De kans op interferentie van de taalnorm is bij de BN-sprekers groter en ingrijpender dan bij de NN-sprekers want BN-sprekers vertonen een grotere taalonzekerheid (bv. Taeldeman 1992: 6). Daarom is de respondenten met opzet niet verteld dat de enquête gericht is op een vergelijking van BN en NN. We hebben ook bewust niet geënquêteerd in de opleidingen taal- en letterkunde. Die studenten zijn door hun opleiding niet meer in staat om onbevangen en onbevooroordeeld deel te nemen aan een enquête over taal; ze zijn zich te zeer bewust van de taalnorm. Om norminterferentie te voorkomen is ten slotte veel zorg besteed aan de formulering van de instructies en de mondelinge introductie. De mondelinge introductie kreeg een informele toon. De enquêteurs noemden zichzelf geen taalkundigen, maar gewoon medewerkers, om iedere associatie met (normatieve) taalkunde te vermijden. We hielden de situering van het onderzoek vaag: ‘een cognitiewetenschappelijk onderzoek naar het taalgebruik van jongvolwassenen’. De enquêteurs spraken de studenten toe in een vlotte nationale tongval, om hen niet in de normatieve sfeer te brengen (de enquêteur in Nederland sprak NN, de enquêteur in België sprak BN). Om de normatieve lading van het begrip ‘voorkeur’ in de instructies weg te nemen (vergelijk het begrip ‘voorkeurspelling’), hebben we expliciet benadrukt dat respondenten hun persoonlijke voorkeur moesten geven. We hebben de respondenten er uitdrukkelijk van af proberen te brengen zich te laten leiden door wat ze tijdens de lessen Nederlands hebben geleerd. Maar ook al hebben we er alles aan gedaan om norminterferentie te weren, uitsluiten dat er enige invloed is geweest, kunnen we uiteraard niet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
DialectinterferentieTegenover norminterferentie staat het risico op dialectinterferentie. Vooral veel BN-sprekers beheersen een dialect en beschouwen dat als hun (enige) spontane dagelijkse taalgebruik. Hun dialect zou hen kunnen inspireren wanneer gevraagd | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 127]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
wordt naar hun ‘persoonlijke voorkeur’. Dat wilden we uiteraard niet omdat ons onderzoek zich niet richtte op dialect maar op bovenregionaal taalgebruik. De kans op dialectinterferentie leek echter niet al te groot, met name doordat de respondenten moesten kiezen uit voorgedrukte zinnen die (met opzet) niet dialectisch zijn. Die zinnen bevatten sowieso elementen die exogeen zijn in hun dialect, waardoor de respondenten ze automatisch in een niet-dialectisch register zouden situeren en ze vanzelf ook in die sfeer zouden antwoorden.Ga naar eind8 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Effect van de enquêteWe moeten nog even terugkomen op de mogelijkheid dat respondenten het onderscheid tussen de twee keuzemogelijkheden zien als een kwestie van ‘goed’ of ‘fout’. Het gevoel dat een van de zinnen fout is, zal waarschijnlijk bij NN-sprekers zijn opgetreden bij het zien van de (vermoedelijke) BN uitdrukkingen, zoals de tweede zin in (3):
Of, om terug te komen op voorbeeld (1), voor Nederlanders is de enig mogelijke lezing van ‘Ik mag geen koffie’ waarschijnlijk iets als: ‘de dokter heeft me verboden om koffie te drinken’. Voor hen heeft die zin dan geen enkel verband met de situatieschets in cursief en hij doet dan ook vreemd aan als antwoord-mogelijkheid. Vlamingen kennen in veel gevallen sowieso de twee uitdrukkingen, dus voor hen is de opdracht niet zo vreemd. Zo bezien was de enquête voor NN-sprekers ook ‘gemakkelijker’; respondenten twijfelden waarschijnlijk minder tussen de twee antwoorden omdat ze de ene mogelijkheid sowieso niet kenden of de zin ongrammaticaal vonden. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4. Enquêteonderzoek: resultatenIn totaal zijn er 933 enquêteformulieren ingevuld. Een aantal werd van verwerking uitgesloten op basis van de persoonlijke gegevens van de respondenten, zoals de factor taalachtergrond: met name onder de geënquêteerden in Nederland bevonden zich veel anders- en tweetaligen. Ook op basis van de controlevragen die we tussen de echte vragen hadden ingevoegd, moesten we een aantal enquêtes buiten beschouwing laten. De controlevragen zagen eruit als echte vragen maar ze hadden niets te maken met ons onderzoeksonderwerp. Bij die vragen was maar één antwoord toepasselijk en wie dat niet had aangekruist, beschouwden we als niet aandachtig genoeg of niet in staat om | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 128]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
de opdracht uit te voeren. Na deze tweevoudige selectie bleven er 716 bruikbare enquêteformulieren over voor verdere verwerking. We hebben een loglineaire analyse gebruikt om per vraag na te gaan welke afhankelijkheidsrelaties er tussen de variabelen bestonden, meer bepaald:
Omdat we per modaal verschijnsel twee verschillende vragen hadden gesteld (zie boven), dienden we na te gaan of het verschil in vraagstelling een effect had gehad op de antwoordkeus. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Variatie tussen BN en NNVoor alle onderzochte verschijnselen op een na hebben we aangetoond dat er een significant verschil is tussen BN- en NN-sprekers. We geven hier enkele voorbeelden; voor verdere resultaten verwijzen we naar Diepeveen e.a. (2006).
De NN-sprekers kiezen massaal voor hoeven (ruim 96%), terwijl de meeste BN-sprekers (ruim 70%) voorkeur voor moeten hebben, zoals te zien is in Tabel 2.Ga naar eind10
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 129]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 130]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tabel 6 vat de resultaten samen. Best is met ruim 80% duidelijk favoriet bij de BN-sprekers, terwijl bijna 90% van de NN-sprekers het beste kiest. Ook hier hebben we te maken met een significant verschil (p=0,000).Ga naar eind11
De kwestie waarvoor we geen significante invloed van het land van herkomst hebben vastgesteld, is het gebruik van de modale infinitief-constructie in de betekenis ‘moeten’, als in het materiaal is nog te betalen ‘het materiaal moet nog betaald worden’. O.a. Hendrickx (2003: 78) merkte op dat dat gebruik van de modale infinitiefconstructie vaak opduikt in BN, maar onze enquête kan geen significant verschil tussen BN en NN aantonen (p=0,074). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interne variatieBij enkele verschijnselen is er naast BN-NN-variatie ook interne variatie aangetoond. In NN is er regionale variatie voor één verschijnsel, namelijk willen versus moeten bij het aanbieden van eten of drinken als in (9) (p=0,028).
Uit Tabel 7 leiden we af dat alle NN regio's de voorkeur geven aan willen, maar in de NN regio Noordwest (zie Kaart 1) is die voorkeur het sterkst met meer dan 95%. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 131]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
In BN zijn diverse verschijnselen regionaal verschillend gebleken. Opnieuw volstaan we hier met een paar voorbeelden; voor een overzicht van de regio's verwijzen we naar Kaart 1.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 132]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Uit het feit dat er in het BN materiaal meer regionale variatie vastgesteld is dan in het NN materiaal, kunnen we afleiden dat er over het gebruik van modale uitdrukkingen onder de Nederlandse respondenten van verschil-lende regio's een grotere eensgezindheid bestaat dan onder de Belgische. De BN variëteit is kennelijk minder ‘gevestigd’ dan de NN variëteit. Als het op taalvariatie aankomt, sluit het zuiden van Nederland zich volgens Haeseryn (1996: 124) in zekere mate aan bij België. Voor modaliteits-uitdrukkingen wordt dat niet bevestigd in het enquête-onderzoek. Bij geen van de onderzochte verschijnselen verschillen de antwoorden in de NN regio Zuid significant van de overige NN regio's. In de NN regio Zuid kiezen respondenten dezelfde antwoorden als de andere geënquêteerde NN-sprekers en doorgaans wijken die antwoorden significant af van de antwoorden van de BN-sprekers. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5. SlotbeschouwingHoe spontane spreekdata en testdata elkaar kunnen aanvullen en wat de voordelen zijn van een gecombineerde verzameling van spontane data én testdata, is beschreven door Cornips (1995: 111). Haar bevindingen worden door ons onderzoek bevestigd. Voor alle kwesties die naar de enquête zijn doorverwezen omdat het CGN onvoldoende gegevens bood, hebben we statistisch betrouwbare resultaten verkregen, die op één geval na ook statistisch significant zijn. Een methodologisch punt dat we nog aan moeten stippen, is dat de resultaten van corpuslinguïstisch onderzoek en van enquêteonderzoek elkaar wel kunnen aanvullen, maar dat ze niet zo maar ‘bij elkaar opgeteld’ kunnen worden. Er is nu eenmaal een kwalitatief verschil tussen authentiek taalmateriaal in het corpusonderzoek versus geconstrueerde voorbeelden (met geëliciteerde oordelen) in de enquête. Het valt niet uit te sluiten dat corpus- en enquête-onderzoek een verschillend resultaat opleveren voor hetzelfde fenomeen.Ga naar eind12 We moeten dus voorzichtig zijn met ‘algemene’ conclusies over BN-NN-variatie. Niettemin is duidelijk gebleken dat de combinatie van corpus- en enquête-onderzoek zeer vruchtbaar kan zijn. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 134]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Bibliografie
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||