
Tabu. Jaargang 38
(2009-2010)– [tijdschrift] Tabu–
[pagina 110]
| ||||||||||||||||||||||
Modaliteit als parameter:
| ||||||||||||||||||||||
1. AchtergrondLerdahl en Jackendoff (1983), Gilbers (1984, 1987), Gilbers en Schreuder (2002) en Schreuder (2006) tonen aan dat spraak en muziek veel gemeenschappelijke eigenschappen hebben. Deze overeenkomsten vormen het uitgangspunt voor Van Eerten et al. (2006) om de intonatiepatronen van de spraak van de Winnie de Poeh karakters Teigetje (vrolijk) en Iejoor (verdrietig) te onderzoeken op verschillen in modaliteit. Muziekstukken met een majeurmodaliteit worden in het algemeen waargenomen als vrolijk en muziekstukken met een mineurmodaliteit klinken eerder droevig. De vraag is of dergelijke modaliteitsverschillen zich ook voordoen in spraak. Van Eerten et al. lieten leerkrachten van een basisschool passages voorlezen uit de verhalen waarin de karakters van Teigetje en Iejoor voorkomen. In de gevallen waarin het bepalen van het type modaliteit mogelijk was, vonden ze bij Teigetje alleen majeur en bij Iejoor alleen mineur. Liberman (2006) verbetert de methode van Van Eerten et al. door | ||||||||||||||||||||||
[pagina 111]
| ||||||||||||||||||||||
fragmenten van maximaal 10 seconden te onderzoeken. Daarmee wordt het risico op spontane modulaties, toonsoortveranderingen, in het akoestische signaal geminimaliseerd. Ook Liberman vindt modaliteit, maar is toch niet 100% overtuigd, omdat ‘Eeyore is stereotypically (since the Disney movie, at least) someone who signals a depressed state by speaking almost in a chant, in which minor-third intervals are prominent.’ Ons onderzoek kan gezien worden als een vervolgonderzoek op Van Eerten et al. (2006) en Liberman (2006). We onderzoeken de hypothese dat modaliteit vaker voorkomt in geacteerde spraak dan in spontane spraak. Luisteraars zijn goed in staat het verschil tussen geacteerde en spontane spraak op te merken (Campbell, 2001; Mathon & de Abreu, 2007). Dit is onder andere te verklaren door een verschil in gebruik van pauzes. Zo blijkt dat pauzes in voorgelezen spraak (of: niet-natuurlijke spraak) korter zijn dan in spontane spraak (of: natuurlijke spraak) (O'Connell & Kowal, 1972; Kowal, O'Connell, O'Brien & Bryant, 1975). Howel en Kadi-Hanifi (1991) tonen aan dat in voorgelezen spraak minder pauzes voorkomen dan in spontane spraak. Ook de plaats van pauzes is verschillend. In spontane spraak valt 55% van alle pauzes op een grammaticale grens (Henderson, Goldman-Eisler & Skarbek, 1966), waar in voorgelezen spraak de pauzes bijna altijd samenvallen met een grammaticale grens (Levin, Schaffer & Snow, 1982). Levin, Schaffer en Snow (1982) lieten 4 onderwijzers verhaaltjes vertellen en voorlezen. Het opgenomen materiaal werd in fragmenten van 10 seconden geknipt. Uit de helft van de fragmenten werd de semantische informatie uit het signaal gefilterd. 11 proefpersonen gaven zowel in de gefilterde als in de nietgefilterde fragmenten in de meeste gevallen correct aan of het om voorgelezen of vertelde spraak ging. Behalve het verschil in gebruik van pauzes blijkt dat in voorgelezen spraak 1) de spreeksnelheid hoger ligt, 2) minder valse starts en herhalingen voorkomen, 3) het ritme constanter is en 4) klinkerverlengingen zeldzamer zijn. Voorgelezen spraak is niet spontaan en lijkt qua eigenschappen meer op geacteerde spraak. Toch tonen Rusko, Trnka, Darjaa, Kovac en Hamar (2008) aan dat er ook verschillen zijn tussen voorgelezen en geacteerde spraak. Zij concluderen dat de toonhoogte aan het eind van de zin van in het Slowaaks voorgelezen spraak meer omlaag gaat dan in geacteerde spraak. Verder blijkt dat voorgelezen spraak langzamer is dan geacteerde spraak. Gunkle (1968) concludeert dat spontaan klinkende taal langzamer is, tempowisselingen en meer stiltes heeft en minder moeite lijkt te kosten. Luisteraars maken bij het beoordelen van fragmenten op spontaniteit dus gebruik van de volgende eigenschappen in het signaal: spreektempo, aantal, lengte en posities van pauzes en ritme. Wij zouden aan dit rijtje een andere prosodische eigenschap willen toevoegen: modaliteit, in ons onderzoek meerdere frequentiepieken in spraakfragmenten van maximaal 10 seconden. Het type modaliteit hebben we opgesplitst in mineur, majeur en ongedefinieerd. Wij zullen in dit onderzoek aantonen dat in geacteerde spraak meer modaliteit | ||||||||||||||||||||||
[pagina 112]
| ||||||||||||||||||||||
voorkomt dan in spontane spraak. | ||||||||||||||||||||||
2. MethodeVoor het verkrijgen van spontaan vrolijke spraak hebben we bij 22 vrouwen tussen de 18 en 34 korte interviews afgenomen in het Nederlands en die opgeslagen als .wav-bestanden. De geïnterviewden variëren in leeftijd van 18 tot 25 en hebben Nederlands als moedertaal. We hebben ervoor gekozen om alleen vrouwelijke proefpersonen te gebruiken voor dit onderzoek zodat sekse geen factor was in onze analyses. In het interview vroegen we onder andere naar de leukste film die de geïnterviewde persoon de laatste tijd had gezien. Vervolgens vroegen we om de leukste scene uit die film te beschrijven. We hebben sommige gesprekken de vrije loop gelaten wanneer we van mening waren dat het spontaan aan de orde gekomen onderwerp ook vrolijke spraak op zou leveren. De geïnterviewden wisten van tevoren dat het interview opgenomen zou worden maar kregen verder geen informatie over het onderzoek. Dit hebben we gedaan om de spontane spraak zo min mogelijk te forceren. Met ‘zo min mogelijk’ bedoelen we dat de spontane spraak af en toe alsnog enigszins geforceerd overkwam omdat sommige geïnterviewden de aanwezigheid van een voice-recorder als nerveusmakend ervoeren. De geïnterviewden zijn na afloop van het interview alsnog geïnformeerd over de inhoud van het onderzoek. Uit de 22 interviews hebben we naar eigen oordeel 92 vrolijk klinkende fragmenten van 5 tot 10 seconden gehaald. Vervolgens hebben we 8 lijsten samengesteld met 14 vrolijk klinkende fragmenten en 6 fillerfragmenten. We hebben in totaal 116 personen verdeeld over de 8 lijsten gevraagd te beoordelen hoe vrolijk ze de fragmenten van een lijst vonden klinken op een Likert-schaal van 1 (helemaal niet vrolijk) tot 5 (erg vrolijk). Om te zorgen dat de semantische informatie niet zou bijdragen aan het oordeel, hebben we de fragmenten eerst gefilterd zodat de spraak niet meer te verstaan was maar de prosodie - de fundamentele toonhoogte - nog wel duidelijk te onderscheiden bleef. Dit hebben we gedaan met behulp van een low-passfilter in het computerprogramma Adobe Audition 3.0. De 21 fragmenten die als vrolijk werden beoordeeld, hebben we uitgeschreven. Deze 21 fragmenten kwamen van 11 personen variërend in leeftijd van 18 tot 25 jaar. De uitgeschreven fragmenten hebben we gebruikt om een script met drie verschillende gesprekken samen te stellen. Het script hebben we vervolgens door 3 actrices laten acteren, waarvan opnames in .wav-formaat zijn gemaakt. De actrices varieerden in leeftijd en acteerervaring. Tijdens de opname hielden de actrices de tekst erbij als geheugensteun. De fragmenten moesten ‘vrolijk’ worden geacteerd en ze zijn aangevuld met andere stukken tekst die op neutrale wijze moesten worden geacteerd. Hierdoor konden we het script tot een beter passend geheel maken en hoefde de actrice niet àlle tekst ‘vrolijk’ te acteren. | ||||||||||||||||||||||
[pagina 113]
| ||||||||||||||||||||||
Door het contrast konden de vrolijke stukken beter worden aangezet. Op de verkregen opnames hebben we vervolgens dezelfde procedure toegepast als hiervoor beschreven. De 21 fragmenten werden uit de opname geknipt, vervolgens werd er een low-passfilter over de fragmenten heen geplaatst. De gefilterde fragmenten werden verdeeld over 4 lijsten aan totaal 57 personen ter beoordeling aangeboden. Voor alle als vrolijk beoordeelde fragmenten hebben we met behulp van een script (De Jong & Wempe, 2009) de syllabes gedetecteerd in PRAAT (Boersma & Weenink, 1992-2010). Daarna hebben we met behulp van een script van Cook (Cook, 2002; Cook, Fujisawa & Takami, 2004) de toonhoogte voor iedere syllabe bepaald. Met een Excel-macro (Cook, 2002; Cook, Fujisawa & Takami, 2004) hebben we vervolgens per fragment de toonhoogtes geclusterd op semitoonafstand. Dit betekent dat de waardes van de toonhoogte omhoog of omlaag werden afgerond naar de dichtstbijzijnde semitoon.Ga naar eind2. De geclusterde toonhoogtes werden vervolgens door een Excel-macro weergegeven in histogrammen. Per histogram, van zowel spontane als geacteerde spraak, hebben we bepaald of er sprake was van één frequentiepiek of van meerdere. In de meeste gevallen was de categorie duidelijk waarneembaar, maar om een aantal twijfelgevallen goed in te kunnen delen hebben we gebruik gemaakt van een formule. De formule kan als volgt worden beschreven: er moeten twee pieken te constateren zijn in een histogram dat het resultaat is van de verwerking van de toonhoogtes van de syllabes in een bepaald (geacteerd of spontaan) gesproken fragment. De horizontale afstand tussen twee pieken moet minstens 2 semitonen zijn, omdat er anders nooit twee pieken kunnen zijn; de verhouding van de verticale afstanden van beide pieken ten opzichte van het laagst tussen gelegen dal mag niet meer dan 2,5 zijn. Zie figuur 1 voor twee histogrammen waarvan de linker een voorbeeld geeft van modaliteit en de rechter het ontbreken van modaliteit weergeeft. | ||||||||||||||||||||||
[pagina 114]
| ||||||||||||||||||||||
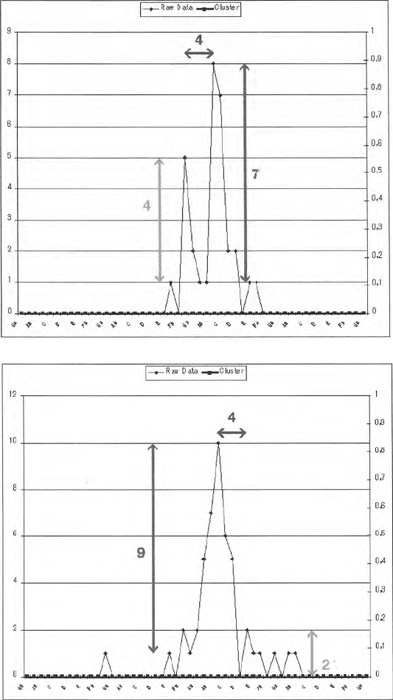 Figuur 1: Twee voorbeeldhistogrammen verkregen voor een spraakfragment: links met, rechts zonder modaliteit.
| ||||||||||||||||||||||
[pagina 115]
| ||||||||||||||||||||||
Vervolgens hebben we gekeken naar de afstand tussen de pieken om de eventuele aanwezigheid van majeur- of mineurmodaliteit vast te stellen. We gaan ervan uit dat de hoogste piek de grondtoon is. Voor majeur is de afstand tussen twee toonhoogtepieken 4 semitonen terwijl dit voor mineur 3 is. Bij een afstand groter dan 4 semitonen is de modaliteit ongedefinieerd. Denk bijvoorbeeld aan powerakkoorden in muziek, waarbij alleen de grondtoon met de kwint gecombineerd wordt en het dus niet duidelijk is of er sprake is van mineur of majeur. | ||||||||||||||||||||||
3. ResultatenVan de 92 geselecteerde gefilterde fragmenten met spontane spraak zijn er 21 als vrolijk beoordeeld op een schaal van 1 (helemaal niet vrolijk) tot 5 (heel vrolijk). Van de 63 gefilterde fragmenten met geacteerde taal (21 per actrice) zijn er 20 beoordeeld als vrolijk op deze schaal. Van de 3 actrices waren dit er 6, 3 en 11. In geacteerd vrolijke spraak zit meer modaliteit (75%) dan in spontaan vrolijke spraak (43%; p < .05; Fisher's Exacte Toets éénzijdig). Van de 20 fragmenten geacteerd vrolijke spraak waren er 5 zonder modaliteit, 10 met ongedefinieerde modaliteit, 4 met majeur modaliteit en 1 met mineur modaliteit. De meeste gevonden modaliteit is dus ongedefinieerd. 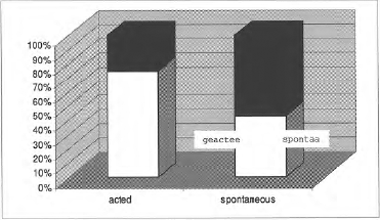 Figuur 2: Percentage fragmenten met meerdere frequentiepieken (witte gedeelte) in links geacteerde en rechts spontane spraak.
Een Kruskal Wallis test laat geen significant verschil zien tussen de vrolijkheidsoordelen voor de 3 types modaliteit (majeur, mineur en ongedefinieerd; χ=2,5; df = 2, p=0,3) bij geacteerd vrolijke spraak. | ||||||||||||||||||||||
[pagina 116]
| ||||||||||||||||||||||
4. Theoretische beschrijving en discussieIn Optimally Theory (OT) (Prince en Smolensky, 1993) verbieden faithfulness constraints de modificatie van inputrepresentaties (Hale & Reiss, 1996), oftewel: deze constraints vereisen dat de oppervlaktevorm gelijk is aan de onderliggende vorm. Articulatory constraints die alleen gebruikt worden in gesproken taal, pleiten tegen ‘articulatory effort’, en wedijveren daardoor mogelijkerwijs met de faithfulness constraints. Vanuit een functioneel perspectief kan gesteld worden dat faithfulness constraints perceptiegemak bewerkstelligen en articulatory constraints articulatiegemak. Belangrijke contraints voor onze theoretiche beschrijving zijn verder cue constraints (Boersma, 2005, 2009). Cues geven ideaalpatronen aan die gekoppeld zijn aan een fonologische representatie en ze spelen een rol bij zowel productie als perceptie. Ons onderzoek heeft als doel aan te tonen dat modaliteit tot de cues behoort voor de waarneming van spraak als spontaan of geacteerd. Net als andere eigenschappen zoals een versneld spreektempo, een verminderd aantal pauzes en een verminderde lengte van pauzes is modaliteit een parameter die geacteerde spraak definieert. Het is een cue met een graduele schaal, hetgeen inhoudt dat er geen specifiek omslagpunt is van niet-modaal naar modaal. Vergelijk maar met sonoriteit. Ook sonoriteit vormt een glijdende schaal met als minst sonorante klanken stemloze explosieven, zoals /t/, en als meest sonorante klanken open vocalen, zoals /a/. Alle andere klanken bevinden zich tussen deze uitersten waarbij bijvoorbeeld vloeiklanken sonoranter zijn dan nasalen. Zoals in de fonologie binnen deze sonoriteitshiërarchie een kunstmatige grens wordt aangenomen tussen fricatieven en nasalen, waarbij de eersten als [-sonorant] worden beschouwd en de laatsten als [+sonorant], zo willen wij ook in de glijdende schaal van modaliteit een omslagpunt aannemen. Dit omslagpunt is arbitrair en waarschijnlijk taalspecifiek. In het onderzoek van Boersma (2005) komt naar voren dat cue constraints aangeleerd zijn; de verschillen tussen talen onderling leveren hier ook evidentie voor. In het Japans en het Engels vinden we doorgaans in de histogrammen van langere fragmenten drie toonhoogtepieken tegenover twee pieken in het Nederlands. Voorwaarde voor modaliteit in het Nederlands is dat er sprake is van twee toonhoogtepieken. De maximale vorm van modaliteit ligt opgeslagen in templaten voor emotionele spraak. Cue constraints geven mineurmodaliteit aan als intonatiepatroon voor sombere spraak en majeurmodaliteit voor vrolijke spraak. Ons onderzoek laat zien dat in spontaan vrolijke spraak significant minder modaliteit voorkomt dan in geacteerd vrolijke spraak. Modaliteit komt in spontaan vrolijke spraak in afgezwakte vorm of zelfs geheel niet voor doordat deze cue in conflict komt met articulatory constraints. Articulatorische lenitieprocessen vanuit een OT-perspectief zijn beschreven door onder andere Kirchner (2001) en Flemming (2006). Lenitie oftewel de minimalisatie van effort-cost bij een articulatorische beweging manifesteert zich in o.a. voicing, degeminatie, elisie, pallatalisatie, nasaal- | ||||||||||||||||||||||
[pagina 117]
| ||||||||||||||||||||||
assimilatie etc. Het is de kunst voor de spreker om met zo min mogelijk energie toch verstaanbaar te zijn. Alle processen die hierdoor veroorzaakt worden, kunnen in één constraint gevat worden, namelijk Least effort (Lazy in Kirchner, 2001). Al deze processen wedijveren met constraints die Least effort blokkeren. In dit geval zijn dat dus de cue constraints voor modaliteit. Als de cue constraint Modaliteit de articulatorische constraint Least effort volledig domineert, zouden de pieken in de histogrammen altijd perfecte tertsen vertonen. Spraak zou dan overeenkomen met zang en ook als zodanig worden waargenomen. In werkelijkheid vinden we in 43% van de spontaanvrolijke-spraakfragmenten modaliteit. In 57% wordt deze modaliteit tenietgedaan door lenitieprocessen. In OT kunnen we dit weergeven met overlappende constraints, zoals weergegeven in Figuur 3.  Figuur 3: overlappende OT-constraints
De luisteraar zal de afwisseling wel- en nietmodaliteit in de intonatiepatronen van spontane taal als natuurlijk ervaren. In ons onderzoek als natuurlijk vrolijk. Pas als modaliteit duidelijk de overhand heeft, waarbij in OT de cue constraint Modaliteit de articulatorische constraint Least effort dus duidelijk domineert, zoals weergegeven in Figuur 4, dan zal de luisteraar de spraak als niet-natuurlijk ervaren. In onze data treffen we 75% modaliteit aan in geacteerdvrolijke-spraakfragmenten.  Figuur 4: overlappende OT-constraints met dominante cue constraint
Om geen onderlinge verschillen te laten bestaan bij luisteraars over de vrolijke intentie van een uiting van een acteur probeert deze de meest onderscheidende waarden (Flemming, 2006) binnen een uiting te gebruiken. Zoals we verwachtten bevat geacteerd vrolijke spraak daarom meer modaliteit dan spontaan vrolijke spraak. Waar de drempel tussen de constraints voor de perceptie van geacteerde spraak precies ligt, kan per taal en ook per individu verschillen. Op een Nederlander kan het dynamische intonatiepatroon van een | ||||||||||||||||||||||
[pagina 118]
| ||||||||||||||||||||||
enthousiaste Amerikaan als geacteerd overkomen, terwijl een Amerikaan dezelfde spraak als spontaan kan interpreteren. In een tweede analyse hebben we het type modaliteit geanalyseerd en een tendens gevonden die we niet met statistiek konden analyseren. Hiervoor waren te weinig fragmenten beschikbaar. De meeste fragmenten hadden een ongedefinieerde modaliteit en slechts één fragment had mineurmodaliteit tegenover 4 fragmenten met majeurmodaliteit. In het onderzoek van Van Eerten et al. (2006) werd er voorgelezen en is er geen enkel fragment van de vrolijke Teigetje gevonden waarin mineurmodaliteit zat. Het enige tegenvoorbeeld dat wij hebben gevonden kan op louter toeval berusten: vervolgonderzoek zal dit moeten aantonen. | ||||||||||||||||||||||
5. ConclusieWe kunnen concluderen dat geacteerd vrolijke spraak meer modaliteit bevat dan spontaan vrolijke spraak. Verschil in de mate van modaliteit in spraak biedt de luisteraar daarmee een cue om spontane vrolijkheid te onderscheiden van geacteerde vrolijkheid. | ||||||||||||||||||||||
[pagina 119]
| ||||||||||||||||||||||
Bibliografie
| ||||||||||||||||||||||
[pagina 120]
| ||||||||||||||||||||||
|
|