
Tijdschrift voor Nederlandse Taal- en Letterkunde. Jaargang 133
(2017)– [tijdschrift] Tijdschrift voor Nederlandse Taal- en Letterkunde–
[pagina 34]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Marieke Olthof,Ga naar voetnoot* Maud Westendorp,Ga naar voetnoot* Jelke Bloem & Fred Weerman
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1 IntroductionA well-known issue in Dutch linguistics concerns the order variation found in verb clusters. A verb cluster can be defined as a combination of two or more verbs in the right periphery of a clause, which typically cannot be interrupted and which have a shared argument structure (Coupé 2015: 1-2). One common type of twoverb clusters consists of a perfective or passive auxiliary and a past participle. In Dutch, these two-verb clusters can both show the order perfective/passive auxiliary - participle, as in (1a) and (2a), and the order participle - perfective/passive auxiliary, as shown in (1b) and (2b):Ga naar voetnoot1
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 35]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
These auxiliary-participle clusters mainly occur with three different auxiliaries: the perfective auxiliaries hebben ‘to have’ and zijn ‘to be’ or the passive auxiliaries worden ‘to become’ and zijn ‘to be’. Since the auxiliary is higher in the hierarchical structure of the cluster than the participle, the auxiliary is called verb 1 and the participle is called verb 2 (Coupé 2015: 19-20; Wurmbrand 2006: 229; Zwart 2011: 296). Consequently, the order auxiliary - participle, shown in (1a) and (2a) is known as the 1-2 order, whereas the order participle - auxiliary, exemplified in (1b) and (2b) is described as the 2-1 order. Longer clusters are also possible, such as a 1-2-3 order, in which case verb number 3 is the participle. The 1-2 order is also known as the ‘red order’, while the 2-1 order is sometimes called the ‘green order’, referring to the colours used for the two orders on dialect maps in an early study on verb clusters by Pauwels (1953). Two-verb clusters are typically divided into two types (Wurmbrand 2004: 44): clusters with a perfective/passive auxiliary and a past participle, exemplified in (1) and (2), and clusters with a modal auxiliary and an infinitive, such as the one shown in (3):
Clusters of the latter type may also have an aspectual auxiliary, a causative auxiliary or a perception verb, instead of a modal auxiliary (Barbiers e.a. 2008: 12). Both clusters with a perfective/passive auxiliary and a participle and clusters combining a modal auxiliary and an infinitive allow two order possibilities: 1-2 and 2-1 (Wurmbrand 2004: 45). However, the auxiliary-participle clusters exhibit a lot more variation than the modal-infinitive clusters, which are used almost exclusively in the 1-2 order nowadays. Dutch verb clusters and their order variation have been the topic of a large number of linguistic studies. Most of these studies focus on subordinate clauses, as these are the only clauses in which all verbs are grouped together (Coupé 2015: 10; Swerts 1998: 300; Zwart 1996: 232). Although Dutch is generally classified as a verb-final language, in its main clauses the so-called ‘verb second’ rule places the finite verb in the second position of the clause (Koster 1975: 111). In main clauses only non-finite verbs occur clause-finally. If a main clause contains two verbs, they do not cluster together. In the present study, we will also discuss subordinate clause verb clusters only. Interestingly, while order variation is usually associated with variation in meaning or information structure, the different orders in verb clusters are generally thought to not express systematically distinct semantics or pragmatics (Coupé 2015: 27; Coussé 2008: 2; De Schutter 2012: 6-7), although some possible semantic associations have been noted (Pardoen 1991; Bloem 2016). Consequently, an important question in the research on Dutch verb clusters is how we can account for this order variation. Many researchers have focused on possible explanations | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 36]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
for the variation that has been observed and on the different factors and circumstances that may affect the choice for one or the other order. Different linguistic and sociolinguistic variables have indeed been shown to influence the choice between the 1-2 and the 2-1 order in particular contexts. This variation can take the form of interspeaker variation, between different speaker groups (such as people from different regions) or intraspeaker variation, where a single person may use both word orders, depending on various factors. In addition, it has been observed that the variation between the two orders has not been stable over time. Therefore, the historical perspective is relevant when studying verb cluster variation. Whereas Dutch around 1400 almost exclusively showed 2-1 orders, over the centuries the 1-2 order has become more and more frequent (Coupé 2015; Coussé 2008). Crucially, Coussé (2008: 190) argues that the change towards more 1-2 orders is still in progress. In previous work, these observations on synchronic and diachronic variation have not been linked empirically. But as ongoing language change typically causes synchronic variation between old and new forms (Labov 1965), and as the availability of the two verb cluster orders has been hypothesized to be caused by related diachronic changes (Van den Berg 1949; Coussé 2008), we may hypothesize that the order variation in two-verb clusters in present-day Dutch also depends on the changing preferences with respect to these orders. The present paper investigates whether the synchronic variation in the orders of Dutch two-verb clusters can indeed be explained on the basis of the diachronic development towards more 1-2 orders, by means of an apparent-time study on spoken Dutch corpus data. We also test whether there is intraspeaker variation, rather than just different people using different word orders. The outline of the paper is as follows. Section 2 addresses the factors that have been shown to affect the choice for a particular verb cluster order. In addition, studies on the diachronic changes in the use of verb cluster orders are reviewed. Section 3 then provides some important theoretical and methodological notions concerning the relation between synchronic variation and diachronic change. In addition, it is shown how these notions lead to predictions about the synchronic order variation in Dutch verb clusters. The method of the study is presented in section 4, which also addresses issues in the data analysis. Subsequently, section 5 contains the results of the study. Finally, section 6 summarizes the outcomes of the study and concludes whether they support the hypothesis that the synchronic order variation in Dutch verb clusters is related to a diachronic change. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2 Background: variation and change in the orders of Dutch verb clusters2.1 Factors influencing the order variation in verb clusters in present-day DutchSince two-verb clusters allow for order variation without obvious semantic or pragmatic correlations, many studies have investigated what may determine the choice for one or the other order. This section summarizes the generalizations that have been made in the literature, starting with more contextual factors that vary between speakers (interspeaker variation) and then moving to more lan- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 37]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
guage-internal factors, which may also affect variation within the same speaker (intraspeaker variation). To start, the regional background of the language user clearly plays a role in the choice between the orders. Different dialects of Dutch show different order preferences (Pauwels 1953; Stroop 1970; Barbiers e.a. 2008: 14-15). For instance, important differences are found between Dutch spoken in Belgium, i.e. Flemish, and Dutch spoken in the Netherlands (De Sutter, Speelman & Geeraerts 2005: 109-11). In Dutch spoken in the Netherlands the 1-2 order is more frequent than in Flemish. In addition, the difference between spoken and written language use seems to play a role in the order variation in Dutch verb clusters (De Sutter e.a. 2005: 114; Stroop 2009: 461). For instance, Stroop (2009: 461) shows that in spoken Dutch, the 2-1 order is preferred over the 1-2 order in perfective/passive auxiliary - participle clusters. According to his data, 2-1 occurs in 63% of the spoken two-verb clusters of this type. By contrast, Arfs (2007: 229) focuses on written Dutch and finds that the 1-2 order is used in 72% of the perfective/passive auxiliary - participle clusters and thus appears more often than the 2-1 order. Thus, the difference between spoken and written language also plays a role in order variation. In relation to these findings it has been noted that many people believe that the 2-1 order is not correct as it is the order used in German (Haeseryn 1990: 40; Stroop 2009; Swerts 1998: 300). For this reason, speakers may try to avoid this order, and they may especially do so in written language, as people tend to follow such normative ideas more strictly in written than in spoken language (Haeseryn 1990: 37). In addition, people may think that the order that they use in their dialect, which is often the 2-1 order, is not correct in standard, written language (De Sutter e.a. 2005: 102). A somewhat related factor affecting the choice between the 1-2 and the 2-1 order involves the register or context of language use. De Sutter e.a. (2005: 122-123) show for instance that in dialogues the 2-1 order occurs more often than in monologues. In addition, clusters in texts that have been edited show more 1-2 orders than clusters in non-edited texts (De Sutter e.a. 2005: 122). The factors just discussed all indicate variation between different contexts, domains and speakers, but there are also factors suggesting intraspeaker grammatical variation, i.e. a single speaker choosing between two possible word orders that are both grammatical and suitable in a particular context. One such factor that has been shown to influence the choice for either the 1-2 or the 2-1 order concerns the type of syntagm, i.e. which kinds of verbs a cluster consists of. Clusters consisting of a modal auxiliary and an infinitive almost exclusively occur in the 1-2 order, whereas clusters with a perfective or passive auxiliary combined with a participle use both the 1-2 and the 2-1 order quite frequently (Bloem, Versloot & Weerman 2016: 11; Coupé 2015: 27-28; Haeseryn 1990: 44-46; Wurmbrand 2004: 43; Zwart 2011: 44). In addition, clusters with the perfective auxiliaries hebben ‘have’ and zijn ‘be’ seem to show more 1-2 orders than clusters with passive auxiliaries zijn ‘be’ and worden ‘become’ (De Schutter 2012: 7-8; Haeseryn 1990: 44-45). A possible explanation for this finding involves the observation that zijn and worden, but not hebben, also function as copulas in clauses with adjectival predicates. In subordinate clauses the copula and adjectival predicate occur in the right periphery, just like verb clusters, but, in contrast | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 38]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
to verb clusters, they always show the order adjective - zijn/worden, as in example (4a) below:
With an adjective, the order in example (4b) is not grammatical, as this sentence is not verb-final. The very similar example (5b) is grammatical, as long as gesloten is interpreted as a participle, not as an adjective. However, it may be dispreferred by analogy with (4b). Thus, the relatively high frequency of the order participle - zijn/worden may be due to analogy with the order of the construction adjective - zijn/worden (De Schutter 2012: 7-8; Haeseryn 1990: 44-45). Associations between particular main verbs and cluster orders have also been found, as well as effects of the semantic class of the main verb (Pardoen 1991; Bloem 2016). Furthermore, a few studies focus on processing complexity (Bloem e.a. 2016; De Sutter 2007). For instance, Bloem e.a. hypothesize that the 1-2 order is easier to process, since it occurs most often in complex contexts, which themselves already require a lot of processing. In easier contexts, by contrast, 2-1 orders occur frequently. Processing complexity thus also seems to play a role in the choice between the 1-2 and the 2-1 order. Researchers such as Arfs (2007) and Swerts (1998) have also focused on the effect of rhythm and prosody on the choice between the 1-2 and the 2-1 order. For instance, Swerts (1998: 304) finds that when the prosodic accent is on the participle, the 2-1 order is preferred. By contrast, when the element directly preceding the verb clusters is stressed, the 1-2 order occurs more frequently (Swerts 1998: 304). Finally, priming may play a role in the choice between the 1-2 and the 2-1 order. Hartsuiker & Westenberg (2000: 36) find that when a clause contains a cluster with a 1-2 order, speakers tend to use the 1-2 order also in a cluster in the next clause. By contrast, a 2-1 order may lead to the use of another 2-1 order in a following clause. This effect occurs both in their spoken and written experiment. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2.2 Diachronic developments in the order variation in Dutch two-verb clustersVarious studies have demonstrated how a variety of linguistic and sociolinguistic factors influence the order variation in verb clusters found in present-day stand- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 39]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ard Dutch. It may be noted however, that these studies generally only take into account the synchronic order variation, while the issue of order variation in verb clusters also has an important diachronic dimension. Diachronic studies have shown that, during the past centuries, the Dutch verb clusters have undergone a noteworthy development with respect to their orders (Coupé 2015; Coussé 2008). Already in the earliest documents used in these studies, from the second part of the thirteenth century, both two-verb clusters with the 1-2 and with the 2-1 order occurred. The variation between the two orders is thus remarkably old (De Schutter 2012: 6-7). However, soon a preference for the 2-1 order arose, leading to the establishment of the 2-1 order as the dominant order around the year 1400. The fifteenth and sixteenth century both showed a preference for the 2-1 order. Then, already during the sixteenth century, a development in the opposite direction began and the use of the 1-2 order started to increase. This change first seems to have affected two-verb clusters with a modal auxiliary, such as zullen ‘shall’, and an infinitive, while clusters with perfective auxiliaries, such as hebben, and passive auxiliaries followed slightly later (Coupé 2015: 104). The increase in the frequency of the 1-2 order in both modal auxiliaryinfinitive and passive/perfective auxiliary-participle clusters continued in the following centuries (Coussé 2008). Looking at present-day standard Dutch, the change towards more 1-2 orders in modal auxiliary - infinitival clusters appears to have proceeded so far that, as discussed in section 1, these clusters now almost exclusively show the 1-2 order. By contrast, the perfective/passive auxiliary - participle clusters still show a high degree of variation between the two orders. Importantly, according to Coussé (2008: 190) in these perfective/passive auxiliary - participle clusters, the change in order preference that started four centuries ago is still ongoing today, and the use of the 1-2 order is thus still increasing. Consequently, this diachronic development may play a role in the variation that can be found in standard Dutch today. An agent-based simulation by Bloem, Versloot & Weerman (2015) was able to account for the change towards the 1-2 order up until the sixteenth century on the basis of frequencies of occurrence of various verb cluster constructions, using an exemplar-based model of interacting language agents. They propose that this change was driven by the grammaticalization of ‘have’ as an auxiliary verb, and by the increasing use of subordinate clauses. However, this model was not able to account for the subsequent change towards 1-2 orders. We should also consider that acquisition plays a role in the historical change from the descending to the ascending word order. Meyer & Weerman (2016) argue that in first language acquisition of verb clusters, the 1-2 order is learned as the default order. Subsequently, children have to discover how and when to deviate from this default. However, as the distribution of 1-2 and 2-1 orders is quite complex, children may acquire a slightly different distribution pattern than that of their parents and other adults. Since the 1-2 order is the default, changes leading to an increase of use of the ‘default’ 1-2 order can be expected here. This way, continuous development in the direction of ascending clusters in combination with a preference for a certain order in acquisition may lead to differences between generations. Interestingly, the acquisitional pathway as proposed by Meyer & Weerman (2016) mimics the pattern of diachronic change in Dutch bipartite clusters. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 40]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Both processes start with modal-infinitive clusters and subsequently generalize the ascending order over all cluster types. Leaving aside regional variation and other contextual factors, the next section discusses the ways in which diachronic changes may be visible in synchronic variation, and formulates a hypothesis about how the diachronic dimension may affect the use of the 1-2 and 2-1 orders in present-day Dutch. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3 The relation between diachronic change and synchronic variation3.1 Synchronic variation and diachronic change connectedSociolinguistic research and studies with a focus on language change have shown that the synchronic and the diachronic dimension of a linguistic phenomenon are directly related (Meyerhoff 2011: 133-134). Synchronic variation is often the source of a linguistic change (Kay 1975; Weinreich, Labov & Herzog 1968). At the same time, diachronic changes often result in synchronic variation (Bickerton 1973; Labov 1965). These observations may also hold for the order variation found in verb clusters. One of the first and most famous studies showing a direct relation between synchronic variation and diachronic change is Labov's study of Martha's Vineyard, an island on the east coast of the United States (1963, 1965). Labov compared his own findings on diphthong pronunciation to results from a number of interviews held thirty years earlier, which reported on the pronunciation of the same diphthongs by speakers from the same island. The data from these interviews showed very little or even no centralization in the diphthongs under investigation, while Labov's own data did show it, and more central pronunciations were produced by younger speakers. Consequently, Labov argued that the centralisation had to be a recent development, and concluded that his data revealed a change in progress. Labov's study shows an example of how synchronic variation between different age groups can be explained as a result of a diachronic change. More specifically, with respect to a particular linguistic phenomenon, younger speakers may represent a newer stage of the language than older speakers. One explanation for this pattern is that each generation acquires the language during the critical period, i.e. early childhood, and that speakers generally do not change their grammars substantially later in life (Boberg 2004: 256; Meyerhoff 2006: 133). Speakers thus keep using the language as it was when they acquired it. Following this line of reasoning, it is in the acquisition process that changes may arise, and indeed, children do often not acquire exactly the same grammar as their parents. Moreover, since each generation in this way shows slightly different language use, children's input may also be somewhat different from that of their parents. In this way, language changes may proceed. As different generations live together and communicate, the differences between them appear as synchronic variation. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 41]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3.2 The apparent-time methodA real diachronic study requires longitudinal data, which may take several decades to gather. This procedure clearly has practical disadvantages, such as the possibility that participants die and the consequence that the researcher must wait many years before results are obtained (McMahon 1994: 240). Researchers who want to investigate a diachronic change may therefore instead make use of the so-called apparent-time method (Labov 1965), which is based on the observation that synchronic variation between different age groups may be due to an ongoing language change (Boberg 2004: 250-251; McMahon 1994: 240). In this method, one compares the synchronic linguistic behaviour of different generations and assumes that the generations reflect different stages of the language. Differences between these age groups may then show that a particular phenomenon gradually increases or decreases in frequency over time. The apparent-time method thus provides a relatively easy procedure to investigate ongoing language changes on the basis of synchronic data. However, data obtained through the apparent-time method that show differences between the various age groups do not always reflect a language change. Differences between speakers of different ages may also be caused by age-grading, i.e. a stable situation with variation between generations (Labov 1965, 1994; Sankoff 2006). Some language features may be associated with a particular phase in life, in that speakers may use a certain feature when they have a particular age but abandon this feature again when they grow older. If this pattern of acquiring and dropping features remains constant through the generations, differences found between age groups are due to age-grading, and no diachronic change is involved. A possible way to decide whether one's data reflect an ongoing change or an agegrading effect is to combine the apparent-time data with real-time data (Boberg 2004: 251; McMahon 1994: 240; Sankoff 2006). Thus, when real diachronic data have already indicated that a change is going on or has been going on, it is very likely that differences between the age groups that suggest a similar change indeed are due to this diachronic change. This strategy was also applied by Labov (1963, 1965), who combined data from earlier interviews with his apparent-time data. Although the apparent-time method has sometimes been criticized for being a theoretical construct rather than a valid practical method, a large number of studies have shown that apparent-time data indeed are able to show ongoing linguistic change, as long as the method is used in the right way (Sankoff 2006). For instance, an important assumption in the method is that language acquisition is limited to the early years of life and that only few changes occur in adulthood. This claim seems to hold mainly for ‘the more abstract levels of grammar, such as phonology and syntax’, which make these domains suitable for the apparent-time method (Boberg 2004: 265). By contrast, lexical knowledge typically develops during life and differences between age groups in lexical knowledge thus do not have to reflect a diachronic change (Meyerhoff 2006: 152). In addition, it has been shown that the apparent-time method is not always able to show the rate of change, but the direction of a change can usually be well attested (Sankoff 2006). If such limitations are kept in mind, the apparent-time method generally seems quite robust (Meyerhoff 2006: 152; Sankoff 2006). In the present study, which focuses on a | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 42]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
syntactic phenomenon and moreover rather investigates the presence than the rate of a change, the apparent-time method is therefore also adopted. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3.3 Hypothesis and predictionsBased on the knowledge about the synchronic variation and diachronic change in the order of the verbs in Dutch two-verb clusters of the type perfective/passive auxiliary - participle, we may now hypothesize that the order variation that is found in these clusters is at least partly due to an ongoing language change. We hypothesize that interspeaker variation may be a result of different generations having different word order preferences, and that intraspeaker variation may be enabled by an ongoing language change, with two competing forms available in the grammar. Diachronic data have shown that while 600 years ago the 2-1 order was very dominant, an increase in the frequency of the 1-2 order has taken place since the sixteenth century, which still may be ongoing. At the same time, synchronic data have shown that there is indeed still variation between the 1-2 and the 2-1 order. The present study therefore investigates whether the change is indeed still proceeding and how this change can be linked to the variation in the order of the verbs today. On the basis of the hypothesis, the prediction is that younger speakers use the 1-2 order more frequently in perfective/passive auxiliary - participle clusters than older speakers, as the younger speakers are expected to reflect a further stage in the diachronic change than the older ones. An apparent-time study focusing on the orders that speakers of different ages use in their perfective/passive auxiliary - participle clusters may show whether this is indeed the case. Speakers of different age groups are compared on their proportions of 1-2 and 2-1 orders. Importantly,
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 43]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
if differences between age groups are found, it is very likely that these indeed reflect language change and not age-grading, since the diachronic data gathered by Coupé (2015) and Coussé (2008) have already shown that a change in order preferences in Dutch clusters has been initiated in the past. If the prediction that younger speakers use more 1-2 orders than older speakers is borne out, we may conclude that Dutch is indeed still undergoing a change in order preferences. Moreover, such a finding may add to our understanding of the synchronic variation in the clusters. By contrast, if the prediction is not borne out, the diachronic change that Coupé (2015) and Coussé (2008) describe may no longer be ongoing. This diachronic change can then not have a direct influence on the synchronic variation in terms of differences between age groups. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4 Method and analysis4.1 Corpus Gesproken Nederlands (CCGN)The data for the apparent-time study on the order variation in perfective/passive auxiliary - participle clusters were taken from the Corpus Gesproken Nederlands (cgn, corpus of spoken Dutch; Oostdijk e.a. 2002), a 10-million word corpus of spoken language from Dutch and Flemish speakers, recorded between 1998 and 2003. The corpus comprises different types of speech, such as conversations with varying degrees of spontaneity, formal and informal speech situations, broadcasted speech and monologues (Oostdijk & Broeder 2003). Table 1 summarizes the text types that are included. Metadata are included for each speaker in the corpus, which make it possible to classify the speakers on the basis of their birth years. In this way, we formed six different age groups, which are shown in table 2:
Each age group covers a period of 10 years, except for the group of oldest speakers, which comprises 15 years, as the data from older speakers is scarcest. Since the data were recorded between 1998 and 2003 and the youngest speakers were born in 1984, the corpus only includes speakers that were 14 years or older. It may therefore be assumed that all data in our study are from speakers that have already fully acquired the language. Previous research has shown that speakers as young as 8 years old may already provide useful data in apparent-time studies (Labov 1994: 49). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 44]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The cgn also includes different types of annotations, which are useful when searching the corpus for particular linguistic phenomena. Two types of annotations are relevant for the present study. Firstly, the whole corpus is annotated with parts-of-speech tags (Van Eynde 2004), which make it possible to search for different parts of speech such as verbs and subordinating conjunctions. Secondly, about 10% of the corpus is syntactically annotated (Hoekstra e.a. 2003). With the help of the syntactic annotations particular syntactic constructions such as subordinate clauses can be found. A potential concern regarding the use of the cgn is that it contains spoken language, while the historical sources that have been used in previous diachronic studies of verb cluster variation contain written language, and no spoken language corpora are available for these time periods. Since mode is a factor in verb cluster variation (De Sutter 2005), it might be the case that verb clusters were also used differently in spoken language than in written language historically. However, the same argument can be made against comparing diachronic written data to synchronic written data - the circumstances under which the texts have been composed are radically different. Other relevant factors that can affect verb cluster variation may also have changed, such as prescriptive norms, formality of the texts, and the level of education and social class of the writers of the available texts. These factors have to be considered in any analysis referring to historical data, whether there is a modality difference or not. Our interest is mainly in the underlying language system, where modality is merely one factor of many affecting the observed variation. Furthermore, we will not perform a direct comparison with historical corpora - the only evidence we need is that there is an ongoing diachronic change that might have enabled the synchronic variation in spoken and written language. A change is observed by Coupé (2015) and Coussé (2008) for the written modality, and for the spoken modality there is no way to find out. In order to find the perfective/passive auxiliary - participle clusters produced in the cgn, we used two different search tools, Parse & Query (PaQu) and the cgn Corpus Exploitation Software (corex). PaQu is an application that was recently developed to enable querying of various Dutch language corpora via a web interface, including the cgn. For a more complete introduction and a demonstration study using PaQu, we refer to Odijk (2015). PaQu is easier to use than most existing querying systems, which often require knowledge of particular query languages, but its basic interface can only search for word pairs. Another easy-touse web-based corpus search engine for Dutch is GrETEL (Greedy Extraction of Trees for Empirical Linguistics), which searches the cgn (Augustinus e.a. 2013) and uses example sentences instead of queries. However, this application does not provide the speaker metadata, such as age, that we require. The two tools can be combined, though, and this is what we did in the present study. The PaQu tool allowed us to search for verb clusters on the basis of the syntactic annotations, while also providing information on speaker age. We composed the queries using GrETEL's example-based querying method, and then ran the resulting XPathexpressions using PaQu's XPath query function. However, because of these tools' reliance on syntactic annotations, they can only search the syntactically annotated part of the cgn. In addition, we therefore used the Corpus Exploitation | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 45]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Software (corex) of the cgn (Kilpatrick & Hellwig 2002), to search the rest of the corpus for clusters on the basis of the parts-of-speech tags. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.2 PaQuSince our study only concerns subordinate clause verb clusters, in the PaQu tool we searched for subordinate clauses. We furthermore specified that the subordinate clauses should contain a form of the verb hebben, zijn or worden with a participle as its verbal complement. We retrieved these verbs both in the 1-2 and the 2-1 order. The queries that we used to search the corpus can be found in the appendix, or reproduced by clicking the numbers in table 3 and 4 below in the electronic version of this article. We then manually went through these results to remove some exceptional cases that do not correspond to our definition of two-verb clusters - they were erroneously retrieved by our search. This was due to the limitations of the standard GrETEL interface, which we used to compose our search queries. While it would have been possible to manually edit the XPath queries output by GrETEL, we chose not to do this, since it is difficult to properly formulate queries manually and exceptional cases are not that common. The first case is verb cluster interruptions, where a non-verbal element occurs inside something that was annotated as a cluster. These could have been excluded from a search by specifying adjacency requirements (i.e. requiring that one verb should be next to the other), but this is not possible in the standard GrETEL interface. Secondly, we manually removed the clusters of more than two verbs from the data, which are included due to GrETEL's greedy extraction method, which automatically matches larger syntactic structures if the specified structure is a part of it. Furthermore, in a few cases the auxiliary and the participle were adjacent to each other, but one of them belonged to the main clause that followed the subordinate clause. These cases were also manually excluded. In this way, 26 items were excluded. Finally, we omitted the clusters by speakers for whom no birth year was included in the metadata. Our search resulted in 2320 two-verb clusters of the type perfective/passive auxiliary - participle. The distribution of the 1-2 and 2-1 orders in these clusters, represented in table 3, shows that, as argued in previous literature, both orders are used relatively frequently and there is no strong preference for one particular order:
By contrast, a quick check showed that the clusters of the type modal auxiliary - infinitive do not show this variation. When searching for subordinate clauses with a form of the verb kunnen, moeten or zullen and an infinitive as verbal complement, only very few examples of the 2-1 order appeared: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 46]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The data in table 4 confirm the claim that the change towards more 1-2 orders in modal auxiliary - infinitive clusters seems to be alm ost completed. In the present study, the focus will the refore only be on perfective/passive auxiliary - participle clusters, for which there is still a large degree of order variation. Importantly, in the search for perfective/passive auxiliary - participle clusters, data from both Flemish and Dutch speakers were included. However, as noted in section 2.1, previous research has shown that the regional background of the speakers has an important influence on the preferred orders. Figure 1, which shows the numbers of clusters by Flemish and Dutch speakers separately, shows that there are indeed also differences between the speakers from the two countries in the data from the cgn. 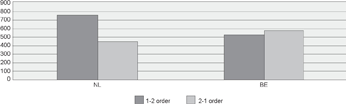
Figure 1 Number of 1-2 and 2-1 orders in perfective/passive auxiliary - participle clusters in the syntactically annotated part of the cgn, by speakers from the Netherlands (nl) and Flanders, Belgium (be)
A Pearson's chi-square test shows that the distributions of 1-2 and 2-1 orders are indeed significantly different for the two countries (χ2 = 55.6429; df = 1; p < .0001). Although this observation may have very interesting implications, such as for instance that the change towards more 1-2 orders may have started earlier or proceeded more quickly in the Netherlands than in Flanders, in the present study our focus is not on regional differences in order preferences. A detailed description of these differences in the cgn data can be found in Stroop (2009). Rather, we want to limit the influence from variables such as regional background as much as possible, in order to be able to zoom in on differences between age groups. Hence, in the search for clusters in our second search tool corex and in the final results only clusters produced by speakers from the Netherlands will be included. Research has also shown that the context or register of speech may have an in- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 47]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
fluence on the order distributions. Figure 2 therefore shows the 2320 perfective/passive auxiliary - participle clusters split by text type: 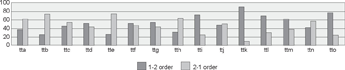
Figure 2 Number of 1-2 and 2-1 orders in perfective/passive auxiliary - participle clusters in the syntactically annotated part of the cgn, split by text type
Figure 2 demonstrates that the distribution of 1-2 and 2-1 orders is quite different per text type. In general, the text types shown on the left side of the figure occur relatively frequently in the 2-1 order. These are the text types with the most spontaneous and informal speech. By contrast, text types containing more formal and prepared language show a preference for the 1-2 order. We may thus conclude from these data that the context and register indeed also influence the use of the orders in our data. However, in the present study we are most interested in spontaneous spoken language. Register has been shown to be a factor affecting verb word order preferences, both in terms of the interactivity of a discourse type as well as in the amount of editorial control over prepared spoken texts (De Sutter 2005: 89). In particular, prepared speech may have been edited by an editor from a different age group. We can control for this by limiting the data set to spontaneous spoken language. In our second search tool corex and in the final results, we therefore only included the text types with the most spontaneous speech, i.e. text types a-d, as shown in table 5. Using only these text types leaves us with 557 clusters from the PaQu dataset for the final results. In Stroop's (2009) study on the use of verb clusters in spontaneous spoken Dutch on the basis of the cgn, the research is also limited to these four text types. It thus seems reasonable to focus on exactly these types.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.3 CorexIn the corex tool we used the parts-of-speech tags to find the examples that matched our definition of verb clusters. As noted in section 4.1, in this tool we excluded the Flemish speakers and limited our search to the text types a-d. Moreover, we excluded all speakers for which no birth year is included in the metadata of the cgn. Finally, as we had already searched the syntactically annotated part of the corpus in PaQu, and the process of checking the corex results is more time | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 48]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Figure 3 Number of 1-2 and 2-1 orders in perfective/passive auxiliary - participle clusters in text type a of the cgn, split by type of subordinate clause
consuming than the process of checking the PaQu results, we excluded this part from our search in the corex tool. In order to find the perfective/passive auxiliary - participle clusters in subordinate clauses, we looked for clauses with a subordinating conjunction followed by a form of the verb hebben, zijn or worden, which in turn had to be followed or preceded directly by a past participle. Since corex allows for specification of such adjacency, all interrupted cluster-like verb groups were automatically excluded. To find subordinating conjunctions, we queried for the vg (voegwoord, ‘conjunction’) part-of-speech tag. Between the subordinating conjunction and the auxiliary verb, between 0 and 100 words were allowed to occur. We then manually removed all examples in which more than one subordinating conjunction occurred or in which the subordinating conjunction did not introduce a subordinate clause with a verb cluster, for instance because the cluster was part of a subordinate clause that itself was embedded in another subordinate clause. Finally, the examples in which either the auxiliary or the participle was part of the main clause instead of the subordinate clauses were omitted. In this way, the corex search resulted in 3418 clusters. A limitation of this search method is that we only selected subordinate clauses on the basis of subordinating conjunctions. However, subordinate clauses may also be introduced by a relative or interrogative pronoun instead of a conjunction. We did not expect an effect of this factor, nevertheless, we compared the word order preferences for subordinate clauses introduced by different pronoun types. Figure 3 shows the distribution of 1-2 and 2-1 orders in subordinate clauses with a subordinating conjunction in text type a and in subordinate clauses with a relative or interrogative pronoun in the same text type. A Pearson's chi-squared test shows that there is no significant difference between the order distributions in the two types of subordinate clauses (χ2 = 2.9523; df = 1; p = .08576). Since there is no effect, we will limit ourselves to clusters in subordinate clauses with a subordinating conjunction. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.4 Analysis methodsFrom the clusters we gathered from the cgn, we took three properties as variables in our subsequent analysis: order, speaker age and cluster type. Speaker age was taken as a categorical variable with the categories shown in table 2, and there are three cluster types: clusters with hebben, zijn and worden. Therefore, all of the variables are categorical. For our analysis, we first performed some descriptive statistics by | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 49]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
creating histograms, and then used inferential statistics to test our predictions. To test for associations between word order and speaker age, we employ the Pearson's chi-squared test for independence. This test is appropriate because all of the variables are categorical, the groups are independent, we are dealing with frequency data, and it does not make any distributional assumptions. Corpus data generally follows a Zipfian distribution, rather than a normal distribution. For a more detailed analysis, we also separated the clusters by cluster types and performed tests on all clusters of a particular type. Section 5 discusses the results of these analyses. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.5 Summary of the selected dataAll in all, the data selected to test our hypothesis are the following: all uninterrupted perfective/passive auxiliary - participle clusters in subordinate clauses produced by Dutch speakers from the Netherlands, born between 1920 and 1984, in the spontaneous conversations, interviews with Dutch teachers and telephone dialogues (text types a-d) in the cgn. From the syntactically annotated part of the corpus we took clusters from all types of subordinate clauses, while from the rest of the corpus only clusters from subordinate clauses introduced by a subordinating conjunction were extracted. There is no overlap between the data sets from corex and PaQu, because the syntactically annotated data searched by PaQu was excluded from the corex query. This combined set of data, a number of 3975 clusters, will be used in the next section, which presents the results of the research. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 ResultsThe data gathered can now be used to test the hypothesis that the synchronic order variation in perfective/passive auxiliary - participle clusters is related to the diachronic change towards more 1-2 orders. This hypothesis predicts that the variation between 1-2 and 2-1 orders is related to different order preferences in our age groups. More specifically, younger speakers would use more 1-2 orders than the older speakers. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5.1 Intraspeaker variationWe will first discuss whether intraspeaker variation is actually present, using only the syntactically annotated section of the corpus (i.e. the section searched with PaQu) as an easily searchable sample of the data. Out of the 147 speakers in this sample, 84 produced more than one verb cluster. 62% of them used both cluster orders, and the highest number of clusters produced by one particular speaker was 11 (five 1-2 orders and six 2-1 orders). Most speakers produced only two or three clusters. Given that despite these low numbers, most speakers produce both orders, we can conclude that there is indeed intraspeaker variation in verb cluster ordering. For this analysis, we used the spontaneous speech text types (a-d) only, and only speakers from the Netherlands, and only from the syntactically annotated part of the corpus. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 50]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5.2 Word order preferences across age groupsAs for the order frequency distributions, figure 4 demonstrates first of all that all age groups show quite a high number of 2-1 orders. Apparently, the 2-1 order is still very frequent in spontaneous spoken Dutch, more so than in written language (cf. Bloem e.a. 2016). Importantly, however, a Pearson's chi-squared test shows that there is a significant association between age group and distribution of 1-2 and 2-1 orders (χ2 = 142.8204; df = 5; p < .0001). This indicates that the variable age or birth year indeed plays a role in the synchronic variation in the perfective/passive auxiliaries, as predicted by the hypothesis. Moreover, as becomes clear in the figure, it is indeed the youngest group that shows the highest proportion of 1-2 orders, and there appears to be a trend of increasing 1-2 order preferences. By computing the Pearson's correlation coefficient, we can see that the birth year groups positively correlate with the percentage of 1-2 orders used (r = 0.913, n = 6, p = 0.011), confirming this trend. Only in this youngest group, there is a preference for the 1-2 order over the 2-1 order, and a post-hoc chi-square goodness of fit test shows that this preference is significant compared to a baseline of 50% preference for each order (χ2 = 14.7827; df = 1; p < .0001). By contrast, all other, older groups, still show a significant preference for the 2-1 order in post-hoc testing.Ga naar voetnoot2 Nevertheless, in general there seems to be an increase in the use of the 1-2 orders with age group, i.e. the younger the age group, the higher the relative frequency of the 1-2 order: 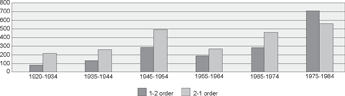
Figure 4 Number of 1-2 and 2-1 orders in perfective/passive auxiliary - participle clusters in subordinate clauses in text types a-d in the cgn, split by age group

Figure 5 Percentage of 1-2 and 2-1 orders in perfective/passive auxiliary - participle clusters in subordinate clauses in text types a-d in the cgn, split by age group
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 51]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
We may thus summarize that the variation between 1-2 and 2-1 orders is indeed associated with age group, and that the younger speakers indeed show more 1-2 orders than the older speakers. Furthermore, the youngest group of speakers suddenly shows a much stronger increase than the older groups. The youngest group also clearly deviates from the older groups in that this group shows a preference for the 1-2 order, while the 2-1 order is still dominant in the older groups. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5.3 Word order preferences across age groups per auxiliary verbThe factor ‘type of auxiliary’ significantly affects word order preferences in our data (χ2 = 53.5147, p < 0.001; df = 2), which is to be expected on the basis of previous studies that found the same. Splitting the results by type of auxiliary yields some additional interesting results. Figure 6 to 8 present the numbers of 1-2 and the 2-1 orders in clusters with the auxiliary hebben, zijn and worden respectively. Note the different scales of the y-axes: the figures show that clusters with hebben occur more frequently than clusters with zijn and worden: a total number of 2086 clusters of the type hebben - participle was found, while the numbers of clusters with zijn and worden are 1352 and 537 respectively: 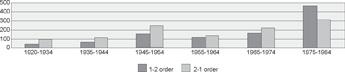
Figure 6 Number of 1-2 and 2-1 orders in hebben - participle clusters in subordinate clauses in text types a-d in the cgn, split by age group
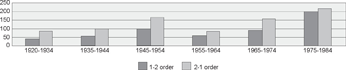
Figure 7 Number of 1-2 and 2-1 orders in zijn - participle clusters in subordinate clauses in text types a-d in the cgn, split by age group
A first important result of the data presented in figure 6 to 8 is that for each type of cluster, i.e. those with hebben, zijn and worden as auxiliary, there is a significant association between age group and 1-2 vs. 2-1 distribution, as shown by Pearson's chi-squared tests over each set of clusters.Ga naar voetnoot3 Thus, for all three cluster types, the distribution of 1-2 and 2-1 orders depends on the age group. Second- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 52]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
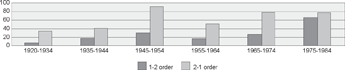
Figure 8 Number of 1-2 and 2-1 orders in worden - participle clusters in subordinate clauses in text types a-d in the cgn, split by age group
ly, for each type of cluster, it is the youngest group that shows the most 1-2 orders. In the case of hebben, a post-hoc chi-square goodness of fit test shows that this group has a significant preference for the 1-2 order (χ2 = 33.4848; df = 1; p < .0001), and all other groups show more 2-1 than 1-2 orders. By contrast, in the zijn and worden clusters more 2-1 than 1-2 orders are found even in this youngest group. However, the preference for the 2-1 order in this group in clusters with zijn and worden is not significant.Ga naar voetnoot4 Finally, for each type of cluster, one can see a general trend showing an increase in the frequency of use of the 1-2 order with birth year: 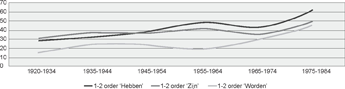
Figure 9 Percentage of 1-2 orders in perfective/passive auxiliary - participle clusters in subordinate clauses in text types a-d in the cgn, split by age group and auxiliary type
Figure 9 shows that the younger groups generally use more 1-2 orders in each type of clusters than the older groups, with again a sudden increase in the use of the 1-2 order in the youngest group. It also demonstrates that the proportion of 1-2 orders is generally larger in the clusters with hebben than in those with zijn or worden as auxiliary. This finding matches earlier research by Haeseryn (1990) and De Schutter (2012) who suggest that this effect may be due to influence from the order adjective - copula. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 53]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
6 Discussion and conclusionThe present study has investigated the hypothesis that the synchronic variation in the order of two-verb clusters of the type perfective/passive auxiliary - participle is partly due to the diachronic change in the use of the different orders. Based on this hypothesis, it was predicted that younger speakers would use more 1-2 orders than older speakers. The apparent-time study has indeed shown that the distribution of 1-2 vs. 2-1 orders is associated with the age group factor. Moreover, the prediction that the youngest group of speakers uses the most 1-2 orders is confirmed, which corresponds to the older diachronic development reported by Coupé (2015) and Coussé (2008). In addition, the overall trend suggests that the frequency of use of the 1-2 order increases with the investigated age groups, i.e. the younger the age group, the more 1-2 orders are found. These results seem to indicate that the different age groups indeed reflect different stages of an ongoing change towards the more frequent use of the 1-2 order, causing synchronic interspeaker variation. Consequently, our hypothesis that the synchronic order variation in verb clusters is related to a diachronic change is borne out. It appears that a diachronic change is ongoing, enabling synchronic intraspeaker variation. We also showed that such intraspeaker variation is present in the corpus. However, the data show a few issues that require further exploration. In the first place, a striking finding is the very sudden increase in the frequency of the 1-2 order in the youngest group, i.e. the speakers born between 1975 and 1984. This group is the only group with an overall preference for the 1-2 order, and the difference between the 1965-1974 and the 1975-1984 group is remarkably large. If we assume that the variation between the groups is due to a diachronic change, which has already been proceeding for several centuries, such an abrupt increase is quite remarkable. If this is an accurate observation, it may have consequences for the interpretation of language acquisition studies, whose younger subjects can be expected to have a greater 1-2 order preference than the average adult speaker. Several explanations for this finding may be considered. Firstly, the notable distribution of 1-2 and 2-1 orders in the youngest group may be due to age-grading. However, as noted in section 3, age-grading is unlikely when real-time data also indicate a diachronic change, such as Coupé's (2015) and Coussé's (2008) data do in the case of the verb clusters. Secondly, it is possible that, in contrast to our assumption, the youngest speakers have not fully completed their acquisition of the verb clusters and their order variation yet and may thus still be developing their order preferences. Following research on the acquisition of verb clusters, this scenario seems possible. Meyer & Weerman (2016) argue that the 1-2 order is the default order for clusters and that after an initial stage in which only 2-1 orders are used, due to analogical pressure from the object-verb word order, children tend to prefer the 1-2 order. In this development, the modal auxiliary - infinitive clusters seem to precede the perfective/passive auxiliary clusters. According to Meyer & Weerman, extra-linguistic factors may in the end lead to an adult-like, more balanced distribution of the 1-2 and 2-1 orders. One possibility is then that it takes children relatively long to abandon their 1-2 preference in favour of a more balanced distribution. However, in this scenario, the young speakers would be moving away from written and | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 54]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
formal word order preferences (the 1-2 order is more prevalent in these domains) during their adolescence, which seems unlikely. Thirdly, we may note that the 2-1 order is used more frequently in dialects. It is often assumed that the use of dialects steadily declines, especially among younger speakers (Barbiers 2005: 8-9; Barbiers e.a. 2005). One possibility is thus that the youngest group is those with fewest dialect speakers, which may have led to a reinforcement of the increase in the frequency of the 1-2 order in this group. A second question that emerges on the basis of the patterns found in the research is how and why this change towards more 1-2 orders is going on and has been going on for so many years. Here, previous research may provide some suggestions. On the one hand, many of the factors that have been proposed to account for the synchronic variation in Dutch verb clusters probably do not have a stable effect over time. For instance, as discussed in section 4.1, the influence of regional background or style and register probably changes during 600 years. On the other hand, factors such as processing complexity may be able to stimulate a linguistic change over time: if the 1-2 order is indeed easier to process than the 2-1 order, this difference between the orders may play a role at all times. Furthermore, the development towards the 1-2 order fits the observation that 2-1 orders are vulnerable in language acquisition and contact situations. As discussed by Meyer & Weerman (2015), a comparison between English, Dutch, and German shows that language contact tends to lead to more 1-2 orders. English is the language that has experienced most language contact of these three languages and is also the language that only allows 1-2 orders. German, by contrast, has had relatively little language contact and allows only 2-1 orders. Dutch has had more language contact than German but less than English, and allows both the 1-2 and the 2-1 order. The availability of 1-2 and 2-1 orders shows a typical ‘Germanic sandwich’ pattern, with Dutch taking a typological position between German and English. This pattern has been observed for various other phenomena (Van Haeringen 1956), and has been linked, among other factors, to the extent to which these languages have been influenced by language contact (Weerman 2006). Over time, this moderate degree of contact may have led to a slow rise in the frequency of the 1-2 order. In their agent-based model study, Bloem e.a. (2015) cannot account for the Dutch change towards 1-2 orders purely on the basis of shifting frequencies of verb cluster features, while this model does account for the current state of English and German. They speculate that language contact or standardization would be a logical explanation for the change in Dutch. This would also mean that the apparent sudden increase in use of the 1-2 order among the youngest group could be explained as a consequence of increased language contact, for example, with the English language, which only uses 1-2-like ordering in verb groups. It would be interesting to study a population of bilingual speakers to see whether such a word order preference transfer could take place. Furthermore, language contact has already been observed to affect verb cluster order in Frisian (Koeneman & Postma 2006; Hoekstra & Versloot 2016), showing that verb cluster orders can be sensitive to language contact. However, another possibility is that the apparent recent increase in 1-2 order use is simply the S-shaped curve that one often finds in processes of language change - change is most rapid around the 50% threshold point, where the alterna- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 55]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
tive form takes over from the previous form as the most dominant form. Indeed, our observations show 55% 1-2 orders in the youngest group, and 38.9% 1-2 orders in the second youngest group, which is around the 50% threshold. Therefore, an increase in the rate of change may not require a separate explanation at all. Written historical sources could be used to provide additional evidence regarding the diachronic change. They, too, could be classified into more formal and less formal text types, and a study of verb clusters in the less formal text types could then provide more evidence indicating when the change might have started. It may be the case that the change started earlier in more formal registers, as there is evidence that the 1-2 order is stylistically preferred (De Sutter 2005). This difference could also be compared to the synchronic differences in word order preferences per register. Finally, it may be interesting to consider that the 2-1 order is still quite frequent in spontaneous spoken Dutch, more so than in written language. The data by Coupé (2015) and Coussé (2008) show that the development towards more 1-2 orders started at least five centuries ago, in written language. And as was discussed earlier, present-day written Dutch shows a stronger preference for the 1-2 order. These observations suggest that the change towards more 1-2 orders may have progressed further in the written than in the spoken language, or it may even have started sooner in the written modality. This is an unexpected possibility, as language changes typically seem to take place earlier and faster in spoken than in written form. For future work, we suggest an apparent time study similar to the present study on a written corpus for which writer age metadata is available. All in all, the present study has shown that in investigating the synchronic order variation in Dutch verb clusters, the diachronic dimension should also be taken into account. The research has provided empirical evidence showing that the change towards more 1-2 orders is still ongoing and that it leads to differences between speakers of different ages and thus to synchronic variation. Furthermore, the data presented in this study adds to our understanding of the most recent stage of this ongoing language change. In this way, the paper has tried to connect the synchronic and diachronic dimension of Dutch verb clusters and has hopefully contributed to the understanding of both the synchronic variation and the diachronic changes in the orders of Dutch two-verb clusters. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
References
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 56]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 57]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 58]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[Om privacyredenen is dit tekstgedeelte niet zichtbaar.] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 59]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
AppendixXPath queries used with PaQu, generated by GrETEL. For reasons of space, we have only printed four representative queries out of the twelve that were used. Results for the other verbs can be found by replacing the verbs in the queries. In the electronic version of this article, the titles of the queries can be clicked to view the results in PaQu. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1. Verb clusters with hebben and a participle in the 1-2 order | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2. Verb clusters with hebben and a participle in the 2-1 order | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 60]
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. Verb clusters with kunnen and an infinitival main verb in the 1-2 order | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4. Verb clusters with kunnen and an infinitival main verb in the 2-1 order |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||