
Historische taalkunde
(1996)–Cor van Bree–
[pagina 31]
| ||||||||||||||||||||||||||||||||||||||||||||
Deel 1 | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 33]
| ||||||||||||||||||||||||||||||||||||||||||||
2. Het vaststellen van taalverwantschap2.1. Inleidende opmerkingenDit hoofdstuk gaat over taalverwantschap: hoe tonen we aan dat bepaalde talen verwant zijn en in welke mate ze dat zijn? De voorbeelden waarmee we een en ander illustreren, zoeken we dicht bij huis; we gaan dus aan de slag met talen waarmee het Nederlands meer of minder verwant is, en zullen zo de families en subfamilies vaststellen waartoe het Nederlands gerekend mag worden. Als we van twee talen, A en B, beweren dat ze met elkaar verwant zijn, dan impliceert dat dat ze op een gemeenschappelijke oorsprongstaal (prototaal) teruggaan. Het impliceert ook dat één taal zich in twee of meer talen kan splitsen. Als een sociologische voorwaarde daarvoor kan men formuleren dat een deel van de bevolking emigreert en, bijv. door een hoge bergrug of een ontoegankelijk moeras, van het andere deel van de bevolking geïsoleerd raakt. Een splitsing zouden we ons inderdaad op deze wijze kunnen voorstellen. We zullen later zien dat we hier slechts één van de mogelijke taalveranderingsscenario's hebben; voorlopig valt echter met deze voorstelling van zaken te werken. Het ligt voor de hand als we willen vaststellen of talen verwant zijn en in welke mate ze dat zijn, dat op grond van gemeenschappelijke kenmerken te doen. Dat moeten dan wel ‘overgeërfde’ kenmerken zijn, d.w.z. kenmerken in A en B die uit de oorsprongstaal C afkomstig zijn. Daarnaast bestaat de mogelijkheid dat ze kenmerken gemeen hebben die ze van elkaar hebben overgenomen, aan elkaar hebben ‘ontleend’. Zo heeft het Nederlands heel wat woorden die we in het Frans terugvinden: visite, parfum, garderobe, beige, chauffeur. Dit zijn echter woorden die het Nederlands uit het Frans heeft overgenomen. Bij de selectie van de kenmerken zijn de volgende criteria van belang:
| ||||||||||||||||||||||||||||||||||||||||||||
[pagina 34]
| ||||||||||||||||||||||||||||||||||||||||||||
Het spreekt vanzelf dat niet met kenmerken gewerkt kan worden die we in alle bekende talen terugvinden (universele kenmerken). Nu kunnen talen in velerlei opzichten overeenkomsten en verschillen vertonen. In de volgende paragraaf zullen we de verschillende soorten kenmerken in ogenschouw nemen. | ||||||||||||||||||||||||||||||||||||||||||||
2.2. Werken met kenmerken2.2.1. De woordenschatOm maar meteen met de deur in huis te vallen: als we taalverwantschap willen vaststellen, is het het beste met een bepaald deel van de woordenschat aan het werk te gaan. Op het eerste gezicht lijkt dat vreemd: immers, er is geen taalsector meer aan verandering onderhevig dan nu juist de woordenschat (vgl. punt a in 2.1): woorden verdwijnen omdat de dingen waarvoor ze gebruikt worden, verdwijnen of omdat ze niet langer als netjes worden beschouwd, nieuwe woorden raken in gebruik om nieuwe dingen te benoemen of reeds bestaande krijgen er met het oog daarop een betekenismogelijkheid bij enz. Verder is de woordenschat dat deel van de taal dat het meest bloot staat aan vreemde beïnvloeding (ontlening) (vgl. punt b in 2.1). Terwijl men om grammaticale veranderingen te constateren vaak lange tijd moet overzien, kunnen de veranderingen in de woordenschat gemakkelijk tijdens een mensenleven worden gesignaleerd. Bij nader toezien blijken deze constateringen echter te somber te zijn. Er is nl. één deel van de woordenschat waarvoor de genoemde feiten niet gelden, dat deel dat wel wordt aangeduid met de term centrale of primaire woordenschat. Dat is een wat vaag begrip, waarmee echter toch goed te werken valt en dat we bij benadering kunnen definiëren als die verzameling woorden die gebruikt wordt voor zaken (referenten) binnen de alledaagse, onmiddellijke, voor alle plaatsen en tijden geldende belevingswereld van de mens: ‘lopen’, ‘zitten’, ‘gaan’, ‘staan’; ‘wolk’, ‘lucht’, ‘regen’, ‘wind’ enz. Een voorbeeld zijn ook de benamingen voor lichaamsdelen, benamingen voor ‘hoofd’, ‘schouder’, ‘arm’, ‘rug’, ‘vinger’, ‘buik’ enz. Dit zijn zaken die voor de alledaagse ervaring van de mens op een directe manier aanwezig zijn. Woorden daarvoor zullen niet snel verdwijnen of aan andere talen worden ontleend. Niet op een dergelijke wijze gegeven zijn ‘lichaamsdelen’ die door de wetenschap pas vrij recent onderscheiden worden; daar zullen we dan ook wel eens vreemde termen voor aantreffen zonder dat er inheemse naast staan: aorta, hypofyse, thalamus, lymfe enz. De benamingen voor de lichaamsdelen zijn er meteen ook een voorbeeld van hoe moeilijk het is de centrale woordenschat af te bakenen. Benamingen voor lichaamsdelen in de taboesfeer, voor geslachtsorganen bijv., moeten we uitzonderen. Aan de ene kant kunnen om eufemistische redenen vreemde woorden in gebruik komen: penis, testikel, scrotum, vagina, clitoris, aan de andere kant zijn de inheemse woorden sterk aan mode en slijtage onderhevig; het zijn vaak in oorsprong | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 35]
| ||||||||||||||||||||||||||||||||||||||||||||
metaforische benamingen, die dus oorspronkelijk of nog altijd daarnaast voor andere zaken gebruikt worden: lul, piel, pik, roede, schede enz. Ondanks dergelijke afbakeningsproblemen valt er toch goed met het begrip centrale woordenschat te werken. Beter dan door middel van een abstracte definitie kan uit de praktijk, zoals die in de volgende hoofdstukken zal blijken, duidelijk worden wat we er onder moeten verstaan. Het voordeel van het werken met woorden is ook dat de vorm ervan over het algemeen arbitrair is (vgl. punt d in 2.1). De arbitraire woordvorm is duidelijk in het licht gesteld door de beroemde zwitserse taalgeleerde Ferdinand de Saussure. Er is geen voor de hand liggend verklarend verband tussen een zaak, bestaande uit vier muren met daarin een deur en een paar ramen en daarbovenop een dak, en het woord (de woordvorm) huis (en woorden die daarmee te identificeren zijn: Haus, house). In het Frans vinden we een heel ander woord, maison, evenals in het Italiaans, casa enz. Als het verklarend verband er wel zou zijn, m.a.w. als de woordvorm niet arbitrair zou zijn, dan zou het feit dat de betreffende talen voor dezelfde zaken dezelfde, althans identificeerbare woorden hebben, niet een argument voor de stelling zijn dat die talen verwant zijn; de overeenkomsten in de woordvorm zouden dan ook met behulp van de aangeduide zaak kunnen worden verklaard. Dankzij de arbitraire woordvorm is het mogelijk taalverwantschap aan te tonen. Een verklarend verband is er bij de klanknabootsingen (onomatopeeën) en de klanksymbolische woorden. Bij deze woorden bestaat wèl een verklarend verband tussen het woord (de woordvorm) en de benoemde zaak: vgl. koekoek, kievit, grutto (onomatopeeën); rimram, sloerie (klanksymbolische of klankexpressieve woorden). Overigens is het niet noodzakelijk dat in een bepaald geval een klanknabootsend of klanksymbolisch woord gebruikt wordt: de koekoek had ook met een niet-klanknabootsend woord aangeduid kunnen worden (in die diepere zin blijft de woordvorm dus arbitrair!). Vgl. het klanknabootsende grutto met het franse barge dat niet klanknabootsend is. Het is niet raadzaam bij het vaststellen van taalverwantschap met dergelijke klanknabootsende of klanksymbolische woorden te werken: het is immers goed denkbaar dat talen buiten alle verwantschap om op grond van een bepaald natuurgeluid ongeveer dezelfde woordvorm hebben. Vgl. ndl. koekoek, du. Kuckuck, lat. cuculus, gr. kokkuks, russ. kukúska, skrt. kokilá. De klankovereenkomsten zijn hier te verklaren uit het feit dat de roep van de koekoek nu eenmaal overal eender is en eender klinkt. We kunnen deze overeenkomsten dus niet aanvoeren als bewijs voor de verwantschap van deze talen. Ook als we een taal nemen die met het Nederlands enz. niet bewijsbaar verwant is, het Hongaars, dan vinden we daar ongeveer dezelfde klankvorm: kakukk. (Opmerkelijk is dat de klankvorm niet in alle talen precies dezelfde is; hierin manifesteert zich toch weer het arbitraire principe.) Ten slotte: als twee talen (ongeveer) hetzelfde woord hebben en er is geen sprake van ontlening, dan is de kans op toeval klein (punt c in 2.1). Daarvoor is het aantal mogelijkheden wat betreft het optreden van fonemen in bepaalde combinaties en volgordes te groot.
Samengevat: woorden hebben bij het aantonen van taalverwantschap het voordeel dat de vorm ervan over het algemeen arbitrair is en dat de kans op toevallige | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 36]
| ||||||||||||||||||||||||||||||||||||||||||||
overeenkomsten klein is. Het centrale deel van de woordenschat heeft daarbij nog als voordeel dat er zich weinig verandering en ontlening bij voordoet. | ||||||||||||||||||||||||||||||||||||||||||||
2.2.2. Affixen en uitgangenTot dusver hebben we ons met woorden beziggehouden. Binnen woorden kunnen echter vaak pre- en suffixen en uitgangen onderscheiden worden. Ook voor pre- en suffixen en uitgangen geldt wat we hierboven omtrent de kans op toeval en de arbitraire klankvorm hebben opgemerkt. De stabiliteit van deze elementen is echter niet altijd zo groot; vooral uitgangen kunnen door ‘afslijtings’-processen uit talen verdwijnen: vgl. mnl. ic segghe met mod.ndl. ik zeg. En in sommige nederlandse dialecten blijkt het prefix van het verleden deelwoord verdwenen te zijn: vgl. gronings zegd met stand.ndl. gezegd. Bij pre- en suffixen is ook ontlening niet uit te sluiten: vgl. atypisch met het aan het Grieks ontleende prefix a- en het aan het Duits ontleende suffix -isch en vgl. lekkage met het aan het Frans ontleende suffix -age. Dat uitgangen worden ontleend, is echter een grote zeldzaamheid. Deze elementen spelen daarom in de taalvergelijking een zeer belangrijke rol. Men gaat dan uit van de oudst bekende fasen van talen, waarin de kans dat men ze nog aantreft het grootst is, omdat ze dan nog niet ‘afgesleten’ zijn.
Resumerend: ook bij pre- en suffixen en uitgangen is er het voordeel van de arbitraire klankvorm en is de kans op toevallige overeenkomsten klein. Vooral uitgangen zijn echter nogal eens aan verandering onderhevig en pre- en suffixen blijken nogal eens te worden ontleend. | ||||||||||||||||||||||||||||||||||||||||||||
2.2.3. Andere kenmerkenNu valt er voor het aantonen van taalverwantschap ook nog aan andere kenmerken te denken, bijv. om de belangrijkste te noemen aan syntactische constructies, aan woordvolgorderegels en aan foneemsystemen. Het is niet mogelijk de waarde van deze kenmerken voor het doel waar het hier om gaat, uitputtend te behandelen. Dat syntactische kenmerken kunnen veranderen, blijkt al wanneer we het Middelnederlands met het moderne Nederlands vergelijken. Zo blijkt in het Middelnederlands het adjectief als bepaling zowel vóór als achter het substantief te kunnen staan: die goede ridder, die ridder goet; in het moderne Nederlands is afgezien van een archaïsche rest als God almachtig alleen de eerste volgorde mogelijk. Een constructie met een predikatief gebruikt stoffelijk adjectief was in het Middelnederlands nog mogelijk, getuige alle waren si (nl. grote coppen) guldijn; in het moderne Nederlands is die constructie niet meer mogelijk: *alle waren ze gouden. Syntactische kenmerken blijken dus aan verandering onderhevig te zijn. Hiertegenover staat dat het minder vaak voorkomt dat de ene taal de andere in syntactisch onzicht beïnvloedt. | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 37]
| ||||||||||||||||||||||||||||||||||||||||||||
Overzicht: GotischHet Gotisch is een germaanse taal die ons uit de 4de eeuw na Christus is overgeleverd, voornamelijk in de fragmentarisch bewaard gebleven bijbelvertaling van bisschop Wulfila (ca. 311-383). Wulfila maakte zijn bijbelvertaling voor zijn gekerstende Goten op het Balkanschiereiland. Het Gotisch mag weliswaar niet zonder meer met het Oergermaans worden geïdentificeerd maar zal daar nog niet ver van afgestaan hebben; het laat ons dus ten naaste bij zien hoe het Oergermaans, waarop ook het Nederlands teruggaat, eruit zag. Wulfila gebruikte in zijn vertaling een eigen alfabet; volgens traditie wordt echter bij de weergave van de gotische woorden een transcriptie, voor een groot deel met latijnse lettertekens, gebruikt. | ||||||||||||||||||||||||||||||||||||||||||||
UitspraakIn het Gotisch komen klanken voor die in het Nederlands niet meer teruggevonden worden: de [þ] <þ> in þu enz. (als de <th> in engels thin); de stemhebbende pendant daarvan: [đ] <d> (na vocaal) in þiudinassus (als de <th> in engels there); de [g] <g> in gif en in de combinatie [ŋg] <gg> in briggais (het Nederlands heeft die klank wèl door assimilatie van k aan d in zakdoek); de [ku] <q>, een k met gelijktijdige lippenronding (een labiovelair) in qimai. Ook had het Gotisch lang aangehouden consonanten, zogeheten geminaten, bijv. in atta (let op de dubbele t-spelling). | ||||||||||||||||||||||||||||||||||||||||||||
MorfologieSubstantieven. Het Gotisch is een taal met vijf naamvallen: nominatief, vocatief, genitief, datief, accusatief (telkens singularis en pluralis). Verder zijn bij de substantieven drie genera (masculinum, femininum en neutrum) en verschillende klassen te onderscheiden. Zo is bijv. himinam een dat.plur. (afhankelijk van in) van himins ‘hemel’, een masculiene ‘a-stam’. Voor paradigmata zie 11.2.2.2. | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 38]
| ||||||||||||||||||||||||||||||||||||||||||||
‘hij bond’, letan ‘laten’ - lailot ‘hij liet’, haitan ‘noemen’ - haihait ‘hij noemde’. Op basis o.a. van de praeteritumvorming kunnen de werkwoorden in een groot aantal klassen worden ingedeeld. Let bij de reduplicatie op de herhaling aan het begin van de beginconsonant van de stam. Het Gotisch heeft behalve een indicatief een imperatief (vgl. aflet ‘vergeef’) en een conjunctief (gewoonlijk optatief ‘wensende wijs’ genoemd; vgl. weihnai ‘geheiligd worde’ en andere conjunctieven in het Onze Vader). Interessant is dat het Gotisch nog een niet-omschreven passief heeft: nasjada ‘hij wordt gered’; in de verleden tijd wordt het passief wèl omschreven: bijv. nasiþs warþ ‘hij werd gered’. Verder heeft het Gotisch verschil in persoon (1e, 2e en 3e) en numerus (getal): singularis, pluralis maar ook nog dualis. Vgl. nima ‘ik neem’, nimos ‘wij beiden nemen’, nimam ‘wij nemen’. Dualisvormen komen ook bij de pronomina personalia voor: wit ‘wij beiden’, weis ‘wij’. Uitgebreid is de imperatief: nim, nimadau, nimats, nimam, nimiþ, nimandau resp. ‘neem’, ‘hij moet nemen’, ‘neemt’ (gericht tegen twee personen), ‘laten wij nemen’, ‘neemt’, ‘zij moeten nemen’. | ||||||||||||||||||||||||||||||||||||||||||||
SyntaxisHet gotische Onze Vader vertoont ook in de woordvolgorde afwijkingen van het moderne Nederlands. Het is echter de vraag of die afwijkingen authentiek gotisch zijn. Wulfila blijkt nl. zijn griekse origineel in syntactisch opzicht nogal slaafs te hebben gevolgd. Opvallend is in ieder geval wèl dat zoals ook bekend uit de klassieke talen het pronominale suffix onuitgedrukt blijft: afletiþ ‘hij vergeeft’, tenzij om wille van nadruk (vgl. in het Onze Vader: weis afletam ‘wij vergeven’; zie 12.3). En verder dat het Gotisch al wèl een begin van een bepaald lidwoord heeft (þana hlaif þana sinteinan ‘het brood het dagelijkse’) maar dat een onbepaald lidwoord nog helemaal ontbreekt. In het Gotisch is het goed te zien hoe het bepaalde lidwoord zich uit het aanwijzend voornaamwoord ontwikkelt. Ook fonologische kenmerken kunnen veranderen. We vergelijken hiervoor het 4e-eeuwse Gotisch (zie voor deze taal het overzicht) en het moderne Nederlands. Het Nederlands heeft een reeks van geronde voorvocalen: y̅, ø̅, œ̆. Het Gotisch miste die echter nog; ergens na de vierde eeuw moeten die dus in de ontwikkeling van het oude Germaans naar het Nederlands toe ontstaan zijn. Hier komt bij dat fonemen ook nog wel eens van de ene taal naar de andere kunnen overgaan: vgl. mod.ndl. serre, rose met uit het Frans afkomstige vocalen. Kortom: van de stabiliteit van syntactische en fonologische kenmerken (zijn ze tegen verandering bestand? is de kans op ontlening klein?) kunnen we veel minder zeker zijn dan van die van de centrale woordenschat. Op het probleem van de stabiliteit zullen we in deel 5 terugkomen. Ook de toetsing aan het derde en het vierde criterium (hoe groot is de kans op toeval? hoe voor de hand liggend is het kenmerk?) kunnen de syntactische en fonologische kenmerken niet altijd doorstaan. We hebben al als voorbeeld gezien dat het erg voor de hand ligt dat het adjectief staat in de buurt van het substantief dat door dat adjectief wordt bepaald. Er zijn ook maar drie mogelijkheden: het staat ervóór, het staat erachter of beide is mogelijk. Hierbij is het echter van belang een algemeen overzicht te hebben van wat de bekende talen op het betreffende punt laten zien. Als slechts in een gering aantal talen het adjectief altijd achter het substantief staat, dan krijgt het statistisch gezien meer betekenis wanneer twee talen zo'n consequente achterplaatsing vertonen. Ook bij de constructie met het stoffelijk adjectief zijn er maar twee mogelijkheden: | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 39]
| ||||||||||||||||||||||||||||||||||||||||||||
het kan predikatief gebruikt worden of het kan dat niet. We zouden echter kunnen zeggen dat het voor de hand ligt dat het wèl predikatief gebruikt kan worden. Als in twee talen predikatief gebruik uitgesloten is, zou dat als een voor taalverwantschap relevant feit gewaardeerd kunnen worden. Over de mate van arbitrair zijn van fonemen of foneemcombinaties valt niets te zeggen, aangezien ze op zichzelf geen betekenis hebben (wèl functioneren ze in gehelen, bijv. woorden, die dat hebben). De mogelijkheden op fonologisch vlak zijn kleiner dan op het eerste gezicht lijkt: er zijn wel veel fonemen en veel combinaties daarvan denkbaar, maar die mogelijkheden worden drastisch ingeperkt, doordat bepaalde combinaties fonetisch moeilijk uitvoerbaar zijn en daardoor nergens zullen voorkomen, bijv. een begincombinatie lr-. De kans dat twee talen een fonologische overeenkomst hebben, is dus groter dan op het eerste gezicht lijkt. Verder moeten we verdisconteren dat bepaalde klanken en klankcombinaties in (praktisch) alle talen voorkomen, bijv. m, n, a; ma, na, am, an; overeenkomsten wat die klanken en combinaties betreft zeggen dus weinig of helemaal niets. (Let wel: het gaat hier om overeenkomsten op het vlak van fonologische systemen, niet om overeenkomsten tussen concrete woorden (of uitgangen en affixen) als in het geval ndl. wind - du. Wind. Dan is de kans op toeval veel kleiner: zie 2.2.1.)
Samengevat: het arbitrair zijn en de geringe kans op toeval blijken bij syntactische kenmerken veel problematischer te zijn dan bij de centrale woordenschat, de geringe kans op toeval ook bij de fonologische kenmerken. Bij beide soorten kenmerken is er een niet geringe kans op verandering of ontlening. | ||||||||||||||||||||||||||||||||||||||||||||
2.2.4. SamenvattingDe overwegingen in de vorige paragrafen zijn in een matrix (schema 2) weer te geven. Deze spreekt na de voorafgaande beschouwingen goeddeels voor zichzelf. Van de onomatopeeën e.d. vermelden we nog dat ze praktisch nooit ontleend worden maar, als weinig officiële woorden, wèl sterk aan verandering onderhevig zijn.
(S1 = stabiliteit 1: in welke mate tegen verandering bestand? S2 = stabiliteit 2: kans op ontlening klein? T = kans op toevallige overeenkomsten klein? A = is de vorm (voldoende) arbitrair? B = in hoeverre bruikbaar bij het vaststellen van taalverwantschap?) | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 40]
| ||||||||||||||||||||||||||||||||||||||||||||
2.3. Iconen, indexen en symbolenVoor de hand liggende kenmerken kunnen we ook iconische kenmerken noemen, niet voor de hand liggende (arbitraire) symbolische. Een andere terminologie is: gemotiveerd tegenover niet-gemotiveerd. Met deze termen komen we in de tekenleer (semiotiek) terecht. Behalve iconen en symbolen onderscheidt men daarin ook indexen; bij de iconen wordt weer een onderverdeling gemaakt in images, diagrammen en metaforen. Bij elk van deze types en subtypes wordt hieronder een toelichting gegeven.
1. Icoon. Dit is een afbeelding van iets in de werkelijkheid in de ruime zin van het woord.
1a. Image. Dit is een afbeelding in engere zin. Een buitentalig voorbeeld is een portret. Binnen de taal kunnen we denken aan klanknabootsingen en klanksymbolische woorden. Ook in de syntaxis vinden we het imagische principe terug: hoe inherenter (wezenlijker) een bepaalde eigenschap is, des te dichter staat de bewoording ervan bij het substantief dat de zaak in kwestie noemt: vgl. die drie aardige jonge meisjes.
1b. Diagram. Dit is een afbeelding van een bepaalde verhouding in de werkelijkheid. Een buitentalig voorbeeld is de afbeelding van de verhouding tussen bepaalde hoeveelheden (bijv. hoeveel voert Nederland in, hoeveel Engeland? enz.) door middel van staafdiagrammen. Een talig voorbeeld is de verklein-woordvorming: de verhouding tussen iets groots en iets kleins wordt in de taal steeds op dezelfde manier weergegeven door middel van de verhouding tussen grondwoord en grondwoord + verkleiningssuffix (-tje en zijn varianten). Een belangrijke rol speelt de diagrammatische iconiciteit in de syntaxis: zo wordt een als zodanig ervaren verhouding van een bepaalde zaak en een eigenschap daarvan steeds op dezelfde manier uitgedrukt, bijv. door middel van een substantief en een daarbij behorend ervóór of erachter geplaatst adjectief.
1c. Metafoor. Dit is een afbeelding op basis van gelijkenis. Buitentalige voorbeelden zijn wat moeilijk te vinden. In de taal wemelt het echter van (al dan niet verbleekte) metaforen: vgl. (gezegd van een mens) 't is een varken.
2. Index. Een index bestaat bij de gratie van het feit dat in de werkelijkheid de dingen na en naast elkaar bestaan. Een buitentalig voorbeeld geeft het bekende spreekwoord: waar rook is, is vuur. Heel vaak is er zoals in het gegeven voorbeeld, sprake van een oorzakelijk verband: de rook volgt niet alleen op het vuur maar wordt daardoor ook veroorzaakt. Een talig voorbeeld is het aanwijzend voornaamwoord, dat verwijst naar iets in de tekst dat voorafgaat of nog komen moet of naar iets dat gelijktijdig in de situatie aanwezig is (vgl. die man).
3. Symbool. Een voorbeeld buiten de taal is (in de meeste gevallen) de vlag van een land. De nederlandse vlag is rood-wit-blauw maar de rangschikking van de kleuren of de kleuren zelf hadden ook heel anders kunnen zijn. Zoals we al gezien hebben, speelt het symbolische (arbitraire) principe een belangrijke rol binnen de woordenschat. | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 41]
| ||||||||||||||||||||||||||||||||||||||||||||
De onderscheiden types en subtypes komen soms tegelijk voor. Zo heeft het bekende symbool van de Nederlandse Spoorwegen ook iets imagisch: men kan er iets van treinen in zien. Ook vele taaltekens zijn gemengd. We hebben al gezien dat de precieze vorm van onomatopeeën taalspecifiek is (vgl. ndl. koekoek, eng. cuckoo enz.). We hebben hier dus images met symbolische trekken. De verkleinwoordvorming is een voorbeeld van diagrammatische iconiciteit. Dat iets biezonders, iets ‘gemarkeerds’ in de werkelijkheid (nl. het kleine) in een gemarkeerde vorm, een vorm met een suffix, tot uitdrukking komt, is een voorbeeld van imagische iconiciteit. De vorm van het suffix op zichzelf (-tje en niet iets anders) is dan weer symbolisch (arbitrair). Het symbolische (arbitraire) principe speelt zoals we gezien hebben, een belangrijke rol bij het vaststellen van taalverwantschap. In het vervolg van het boek zullen we zien dat we bij taalverandering met indexicaliteit en iconiciteit in aanraking komen. | ||||||||||||||||||||||||||||||||||||||||||||
2.4. Klankwetten en klankcorrespondentiesAls we besluiten met een deel van de woordenschat aan de slag te gaan, zijn daarmee nog niet alle problemen opgelost. Immers, woorden en ook affixen en uitgangen hebben een betekenis- en een klankvormaspect, en we hebben gezien dat ook de klanken (en trouwens ook de betekenissen) kunnen veranderen. Kan dit niet betekenen dat woorden in verschillende talen, die op dezelfde oorsprongswoorden teruggaan, zo ingrijpend en daarbij op zo verschillende wijze, in de ene taal zo, in de andere taal zus, veranderen dat het niet meer lukt ze met elkaar in verband te brengen? Dit zou het geval zijn wanneer binnen een taal een klankverandering per woord op een andere manier zou verlopen. Het blijkt echter dat zo'n klankverandering met een tamelijk grote regelmaat plaatsvindt, reden waarom men dan ook van een klankwet spreekt. Het verschijnsel klankwet zal in een apart hoofdstuk uitvoerig aan
de orde komen, maar we kunnen alvast de volgende definitie geven: een klankwet
is een formule of een formulering waarin men een in een taal regelmatig
optredende klankverandering uitdrukt of kortweg: een klankwet is een in een
taal regelmatig optredende klankverandering. Dat er zulke klankwetten bestaan,
valt eenvoudig door middel van een vergelijking van Middelnederlands en modern
Nederlands te illustreren: vgl. mnl. huus, muus, luden, uut, met
y̅, met de overeenkomende mod.ndl. woorden die daar door
diftongering
| ||||||||||||||||||||||||||||||||||||||||||||
[pagina 42]
| ||||||||||||||||||||||||||||||||||||||||||||
of op gelijke wijze veranderen. Zo vond ook geen diftongering plaats in het Westvlaams (maar wel weer verkorting) met als resultaat de klankcorrespondentie: zeeuws y̆ - wvla. y̆. We verduidelijken dit alles met schema 3.
Schema 3 (klankcorrespondenties en klankwetten) 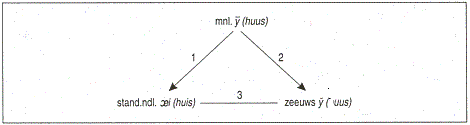 Bij 1, 2 en 3 in dit schema hebben we te maken met klankcorrespondenties, bij 1 en ook bij 2 is daarenboven een klankwet, een klankverandering, in het spel, resp. diftongering en verkorting. Zo'n klankwet is dus regionaal gebonden (wèl in het Hollands, niet in het Zeeuws of omgekeerd) en is ook gebonden aan een bepaalde periode: ergens tussen de middelnederlandse en de moderne periode in. Het bovenstaande betekent dat wanneer we met verwante woorden
werken, deze woorden in de vergeleken talen niet precies dezelfde klankvorm
behoeven te hebben. Wèl moeten er regelmatige klankcorrespondenties te
constateren zijn. Mnl. y̅ wordt regelmatig in het
Standaardnederlands
Er is echter nòg een complicatie, nl. dat dergelijke regelmatige klankcorrespondenties niet tot verwante woorden beperkt zijn; ze treden nl. ook bij leenwoorden op. Dit valt met het volgende geval duidelijk te maken. Het betreft een aantal woorden die vanuit het Latijn in het Nederlands gekomen zijn: lat. presbyter - ndl. priester, breve - brief, speculum - spiegel, Petrus - Pieter. De regelmatige correspondentie die hier optreedt, is lat. ĕ - ndl. ī <ie>. Deze is het gevolg van een aantal regelmatige klankveranderingen (klankwetten) die de ĕ in het Nederlands en eventueel ook in de bemiddelende taal, het Oudfrans, heeft ondergaan. Zoals we zullen zien (in 4.2), is één van de taken van de historisch-vergelijkende taalwetenschap klankcorrespondenties die op verwantschap wijzen, te scheiden van klankcorrespondenties die bij leenwoorden optreden. Het zal duidelijk zijn dat daarbij de aard van de woorden, centrale woordenschat of niet, een gewichtige rol speelt. Hierboven is gesproken van woorden met dezelfde of verwante betekenis. De toevoeging verwant is noodzakelijk omdat woorden, zoals reeds opgemerkt, ook naar betekenis kunnen veranderen. We mogen ze echter met elkaar identificeren zolang de verschillende betekenissen met elkaar te rijmen zijn. Een voorbeeld is ndl. vuil dat met het duitse faul ‘lui’ in verband kan worden gebracht, immers iemand die lui is, is ook vaak vuil. Ons besluit om met de centrale woordenschat en verder met pre- en suffixen en met uitgangen te werken, kunnen we nu preciseren: conclusies van taalverwantschap baseren we op regelmatige klankcorrespondenties bij de genoemde lexicale elementen. Hierbij vergelijken we dus elementen die dezelfde, | ||||||||||||||||||||||||||||||||||||||||||||
[pagina 43]
| ||||||||||||||||||||||||||||||||||||||||||||
althans verwante betekenis hebben. In het volgende hoofdstuk zullen we zien hoe de methode in de praktijk werkt. | ||||||||||||||||||||||||||||||||||||||||||||
2.5. Typologische vergelijkingDe indelingen waartoe we in het volgende hoofdstuk op grond van de centrale woordenschat zullen komen, zijn genetisch van aard; ze zijn inderdaad op verwantschapsrelaties gebaseerd. Een zodanige indeling behoeft (zoals na het in 2.2.3 besprokene duidelijk zal zijn) geenszins parallel te lopen met een indeling op grond van grammaticale kenmerken; een indeling op grond daarvan noemen we een typologische indeling. Zo sluit wat de aanwezigheid van geronde voorvocalen betreft, het Frans aan bij het Nederlands en het Duits, wat betreft de afwezigheid ervan het Engels bij het Italiaans en het Spaans. We zullen echter zien dat volgens de genetische indeling enerzijds het Engels met het Nederlands en het Duits, anderzijds het Frans met het Italiaans en het Spaans moet worden gecombineerd. We kunnen talen typologisch ook met behulp van het naamvalscriterium groeperen, maar ook dan krijgen we een indeling die niet klopt met de genetische. (Betrekkelijk) naamvalsloze talen als het Nederlands en het Engels zijn niet aantoonbaar verwant met het naamvalsloze Chinees maar wel met naamvalstalen als het Latijn, het Grieks, het Sanskrit en het Duits. Ten slotte nog een syntactisch criterium. Het is typisch voor het Nederlands en het Duits dat in de bijzin de persoonsvorm (provisorisch geformuleerd) op één van de laatste plaatsen komt te staan. In het Engels gebeurt dat niet; hierin lijkt het op het Frans. Genetisch hoort het Engels echter bij het Nederlands en het Duits. Vergelijk de volgende zinnen:
We hebben dus twee soorten indelingen: een genetische en een typologische. Of preciezer gezegd: er is één genetische indeling en daarnaast zijn er vele typologische. Met de genetische indeling houden we ons dus in de historische taalwetenschap bezig. |
|
 i hebben: huis, muis, luiden (vgl. kleine
luiden), uit; alleen vóór r treedt deze diftongering niet op:
vgl. mnl. suur, buur, huur met mod.ndl. zuur, buur, huur. Zo'n
regelmatige beperking op een klankwet noemen we een klankwettige
uitzondering. Dergelijke klankwetten leiden tot regelmatige
klankcorrespondenties tussen de betrokken talen. Die correspondenties kunnen
verticaal zijn, tussen talen die chronologisch in elkaars verlengde liggen:
mnl. y̅ - mod.ndl.
i hebben: huis, muis, luiden (vgl. kleine
luiden), uit; alleen vóór r treedt deze diftongering niet op:
vgl. mnl. suur, buur, huur met mod.ndl. zuur, buur, huur. Zo'n
regelmatige beperking op een klankwet noemen we een klankwettige
uitzondering. Dergelijke klankwetten leiden tot regelmatige
klankcorrespondenties tussen de betrokken talen. Die correspondenties kunnen
verticaal zijn, tussen talen die chronologisch in elkaars verlengde liggen:
mnl. y̅ - mod.ndl.