|
| |
| |
| |
Automatische vertaling
Frank van Eynde (Leuven)
Descartes en Leibniz droomden er al van en in 1933 vroeg de Rus Trojanski er
zelfs een patent voor aan, maar de ontwikkeling van vertaalautomaten kreeg pas
echt de wind in de zeilen met de opkomst van de eerste computers in de jaren
veertig. Hoewel die toen vooral voor wiskundige en administratieve toepassingen
werden gebruikt, zag de Amerikaan Warren Weaver er ook andere mogelijkheden
voor, zoals vertalen. In zijn manifest Translation (1949)
vergeleek hij het vertaalproces met het ontcijferen van gecodeerde boodschappen
en aangezien er tijdens de Tweede Wereldoorlog een aanzienlijke expertise was
opgebouwd in het decoderen van zulke boodschappen, zag hij het succes van de
automatische vertaling vol vertrouwen tegemoet:
It is very tempting to say that a book written in Chinese is simply a
book written in English which was coded into the ‘Chinese code’.
If we
have useful methods for solving almost any cryptographic problem, may it not be
that with proper interpretation we already have useful methods for translation?
(Weaver, 1949, p. 22)
Het optimisme van Weaver is intussen al lang weggeëbd en zijn opvatting van
vertaling als decodering is niet houdbaar gebleken, maar de behoefte aan
vertaalautomaten is sterk gegroeid en de ontwikkeling ervan vertoont een gestage
vooruitgang. Als gevolg hiervan is automatische vertaling één van de
belangrijkste computerlinguïstische toepassingen geworden. Op dit moment zijn er
tientallen projecten voor automatische vertaling aan de gang; Japan en Europa
investeren het meest, maar ook in de Verenigde Staten, Canada, Zuid-Amerika en
Zuidoost-Azië wordt er aan de weg getimmerd.
| |
| |
Dit artikel bestaat uit twee delen. Het eerste is thematisch en behandelt de
algemene opbouw van vertaalautomaten; de aandacht gaat daarbij in eerste
instantie naar de taalkundige aspecten van het vertaalproces. Het tweede deel is
historisch; het biedt een kort overzicht van de ontwikkelingen in de
automatische vertaling sinds Weaver.
| |
1. Opbouw van een vertaalsysteem
| |
1.1 Woord voor woord
De eerste systemen voor automatische vertaling waren woord-voor-woord
vertalers; om een zin als
(1) reigers eten vis
in het Engels te vertalen nam de automaat achtereenvolgens de woorden reigers, eten en vis en verving ze
door hun Engelse equivalenten:
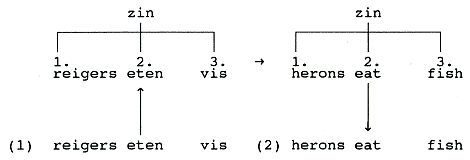
De eerste stap is die van de analyse: de zin wordt verdeeld in de woorden
waaruit hij bestaat en die woorden krijgen een nummer mee. Die worden
dan elk afzonderlijk en met behoud van hun nummer vertaald in het Engels
(reigers → herons, enz.); die stap heet transfer. In de derde stap, de
synthese, worden de Engelse equivalenten samengevoegd tot een Engelse
zin.
De betrouwbaarheid van zulke systemen is gering; bekend is het voorbeeld
van de automaat die nous avions vertaalde in we aeroplanes. Maar de verdeling van het vertaalproces
in drie stappen - analyse, transfer en synthese - is bruikbaar gebleken
en vormt het basisschema van de meeste bestaande syste- | |
| |
men. De precieze invulling van die drie modules is natuurlijk wel
gewijzigd; daarover gaan de volgende paragrafen.
| |
1.2 Morfologie
Een wat gesofistikeerdere variant van de woord-voor-woord vertaler is de
automaat die vóór de eigenlijke vertaalstap (transfer) de woorden
morfologisch ontleedt:
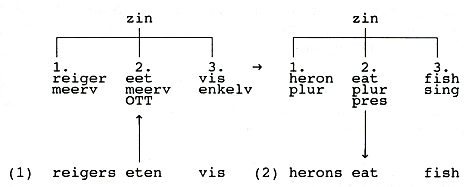
De toevoeging van morfologische informatie maakt een belangrijke
vereenvoudiging van de transfermodule mogelijk. In plaats van aparte
regels voor alle vormen van eten
| eet |
→ |
eats |
| eten |
→ |
(to) eat |
| at |
→ |
ate |
| aten |
→ |
ate |
| gegeten |
→ |
eaten |
volstaat nu een regel voor de stam
en een aantal regels voor de andere bestanddelen
| enkelvoud |
→ |
singular |
| meervoud |
→ |
plural |
| OTT |
→ |
present |
| |
| |
Aangezien die laatste regels algemeen geldig zijn en dus niet voor ieder
substantief of werkwoord apart vermeld worden, wordt er flink bespaard
op het aantal transferregels. Een gevolg van deze werkwijze is wel dat
de synthesemodule ook slimmer moet worden. Die moet nu niet alleen de
woorden op een rijtje zetten, maar ze ook nog vormen: uit de stam heron en het bestanddeel plural moet
bij voorbeeld het woord herons samengesteld worden.
Dit is een algemene tendens bij het ontwerpen van vertaalsystemen: door
de analyse- en synthesemodules complexer en slimmer te maken wordt de
transferstap vereenvoudigd. Dit zal ook uit de volgende paragraaf
blijken.
| |
1.3 Syntaxis
De noodzaak van syntactische analyse blijkt in gevallen waar de woordorde
in brontaalzin en doeltaalzin niet dezelfde is, zoals in
(3) het schijnt dat reigers vis eten
(4) it seems that herons eat fish
De toevoeging van een regel aan de transfermodule die de laatste twee
woorden gewoon van plaats verwisselt zou in dit geval volstaan om een
correct resultaat te bekomen en de eerste vertaalsystemen maakten dan
ook gebruik van dit soort regels, maar de geldigheid van zulke regels is
uitermate beperkt. Bij vertaling van
(5) het schijnt dat reigers veel vis eten
gaat het al fout:
(6) * it seems that herons much eat fish
Hieruit blijkt dat veranderingen in woordorde beter niet in termen van
woorden gedefinieerd worden, maar in termen van zinsdelen: niet de
woorden eat en fish veranderen van
plaats, maar de zinsdelen (much) fish en eat.
| |
| |
Om regels in termen van zinsdelen te kunnen formuleren moeten die laatste
natuurlijk wel als dusdanig herkend zijn en dat is precies de rol van de
zinsdeelanalyse. Voor de bijzin [...] dat reigers veel vis
eten ziet die er zo uit:
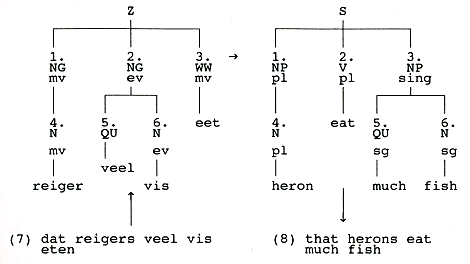
De transfermodule bevat nu niet alleen een vertaalwoordenboek maar ook
een syntactische regel die het werkwoord van de laatste plaats in de zin
naar de tweede plaats brengt:
1 [...] x → 1 x [...]
In dit geval is x gelijk aan 3, maar x kan ook groter zijn, zoals in

Om dit soort van bilinguale transformaties te kunnen uitvoeren is het
noodzakelijk dat de computer automatisch zinsdeelstructuren kan
opbouwen. Met de huidige stand van het onderzoek in de
computerlinguïstiek is dat geen | |
| |
probleem; als men over een
krachtige machine beschikt, is die automatische ontleding een kwestie
van minder dan een seconde. Ter illustratie geef ik de
constituentenstructuur die in het Eurotra-project wordt toegekend aan de
Engelse zin
(11) the commission has sent the proposal to the Council
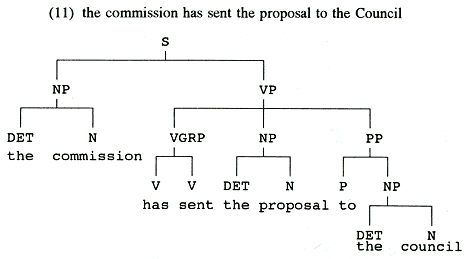
Met de toekenning van constituentenstructuren zijn de vertaalproblemen
nog niet van de baan. Vergelijk
(12) wie hebben jullie gezien?
(13) wie heeft jullie gezien?
Beide zinnen vertonen dezelfde zinsdeelstructuur:
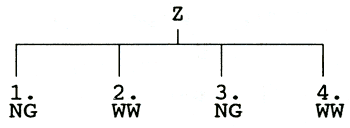
Bij vertaling naar het Engels blijkt er evenwel een verschil: in het
geval van (12) kan de woordorde gewoon bewaard worden, terwijl dat voor
(13) niet kan:
| |
| |
| (14) |
who(m) |
have |
you |
seen? |
| |
1. |
2. |
3. |
4. |
| (15) |
who |
has |
seen |
you? |
| |
1. |
2. |
4. |
3. |
Dit verschil heeft te maken met het feit dat jullie/you
in (12/14) onderwerp is en in (13/15) lijdend voorwerp, maar die
informatie is niet aanwezig in een gewone zinsdeelstructuur. Hij kan er
wel uit afgeleid worden, want in het Nederlands moeten onderwerp en
vervoegd werkwoord in getal overeenstemmen en aangezien hebben en jullie allebei meervoudig zijn en
heeft en wie allebei
enkelvoudig, kan het onderwerp in (12) en (13) geïdentificeerd worden.
Om nu voor transfer beschikbaar te zijn moet die informatie expliciet
uitgedrukt worden en dat gebeurt in de vorm van relationele structuren.
Voor (12/13) zien die er als volgt uit:
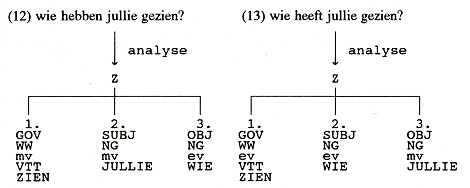
‘GOV’ staat voor governor: het is de kern van een
constructie en heeft als dusdanig een aantal bepalingen, in dit geval
een onderwerp (SUBJect) en een lijdend voorwerp (OBJect). ‘VTT’ staat
voor voltooid tegenwoordige tijd. De andere termen
zijn al eerder ingevoerd.
Een aardig neveneffect van de toekenning van relationele structuren aan
zinnen is dat de volgorde van de zinsdelen er niet meer toe doet. Die is
natuurlijk wel relevant op het niveau van de zin - katten
eten muizen betekent iets anders dan muizen eten
katten - maar op het niveau van de relationele structuur is ze
niet meer relevant omdat het verschil tussen onderwerp en lijdend
voorwerp er niet meer uit de woordorde moet blijken, maar in de | |
| |
structuur zelf vastgelegd is. In plaats van de zinsdelen
precies zo te ordenen als in de zin zelf kan men in de relationele
structuren een uniforme volgorde vastleggen, bij voorbeeld met de
governor voorop, gevolgd door het subject, het object, het meewerkend
voorwerp, de bijwoordelijke bepalingen, enz.
Die volgorde hoeft dan in transfer niet gewijzigd te worden en het is
vervolgens aan de synthesemodule om de zinsdelen in de juiste orde te
plaatsen. We merken hier opnieuw de tendens om de transferstap te
vereenvoudigen door het intelligenter maken van analyse en synthese.
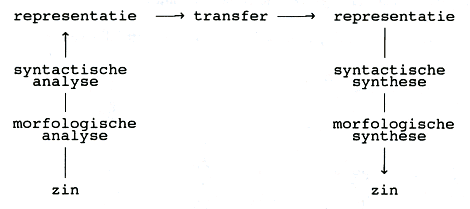
Na de toevoeging van syntactische modules ziet het vertaalmodel er zo
uit:
In de meer geavanceerde systemen worden de zinsdeelgrenzen en
syntactische functies niet alleen bepaald op het niveau van de
oppervlaktestructuur, maar ook op dat van de dieptestructuur. Zo zal aan
de zin
(16) deze reigers schijnen vis te eten
niet alleen een oppervlaktestructuur worden toegekend waarin deze reigers onderwerp is van schijnen en
waarin eten geen onderwerp heeft, maar ook een
dieptestructuur waarin deze reigers onderwerp is van
eten en waarin het onderwerp van schijnen de hele bijzin is:
| |
| |
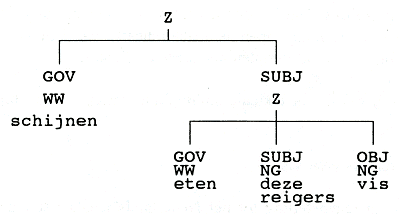
Het voordeel van de toekenning van zulke dieptestructuren blijkt bij
vertaling naar het Frans:
(17) * ces hérons semblent manger du poisson
il semble
que ces hérons mangent du poisson
De functies in de Nederlandse oppervlaktestructuur corresponderen niet
met die in de Franse oppervlaktestructuur, maar op het niveau van de
dieptestructuur is die correspondentie er wel.
| |
1.4 Semantiek
De vraag rijst of systemen met syntactische modules voldoende
gesofistikeerd zijn om alle vertaalproblemen het hoofd te bieden. Het
antwoord daarop is helaas negatief. Vergelijken we bij voorbeeld
(18) paarden zijn verstandige dieren
(19) de paarden zijn de enige stukken die over andere stukken
mogen springen
In de eerste zin gaat het over warmbloedige viervoeters en in de tweede
zin over schaakstukken. In het Engels zijn dat respectievelijk horses en knights. Er bestaat
bijgevolg een keuzeprobleem bij het vertalen en om dat op te lossen is
een morfo-syntactische representatie onvoldoende. Dat paard een substantief is dat in (18) en (19) gebruikt is als de
kern van een nominale groep die de functie heeft van subject, is
allemaal juist en relevant, maar om het keuzeprobleem op te lossen is er
meer nodig: er moeten, primo, twee verschillende betekenissen van paard onderscheiden worden en, secundo, er | |
| |
moeten regels geformuleerd worden die in concrete gevallen kunnen
uitmaken met welk soort paard men te maken heeft. Pas
dan kan de automaat beslissen of hij paard zal
vertalen als horse of als knight.
Een soortgelijk geval van lexicale ambiguïteit treffen we aan bij de
vertaling van
(1) reigers eten vis
in het Duits. In tegenstelling tot het Nederlands maakt het Duits een
onderscheid tussen eten wanneer dat door mensen gebeurt en eten wanneer
dat door dieren gebeurt. Het eerste heet in het Duits essen, het tweede fressen. Om nu te vermijden
dat (1) wordt vertaald als
(20) * Reiher essen Fisch
of dat
(21) studenten eten vis
wordt vertaald als
(22) * Studenten fressen Fisch
moet de automaat iets weten over de betekenis van reiger en student, met name dat een reiger een
dier is en een student een mens.
Het belang van de juiste keuze in zulke gevallen mag onder meer blijken
uit het vaak geciteerde (zij het apocriefe) verhaal over de automaat die
voor
(23) the spirit is willing but the flesh is weak
(de wil
is sterk maar het vlees is zwak)
na vertaling in het Russisch en hervertaling naar het Engels het volgende
produceerde:
(24) the liquor is alright but the meat is spoilt
| |
| |
De ontsporing is te wijten aan het feit dat het Russisch eenzelfde woord
gebruikt voor geest en geestrijke
drank evenals voor flesh en meat (dat laatste geldt overigens ook voor het Nederlands). Door
in beide gevallen de foute keuze te maken bij terugvertaling naar het
Engels verkrijgt men (24).
Semantische problemen doen zich overigens niet alleen voor bij het
vertalen van lexicale elementen zoals substantieven en werkwoorden, maar
ook bij gegrammaticaliseerde morfemen zoals werkwoordstijden,
lidwoorden, hulpwerkwoorden, voornaamwoorden, en dergelijke. De
problemen met lidwoorden blijken bij vertaling van
(1) reigers eten vis
in het Frans:
(25) les hérons mangent du poisson
* hérons mangent
poisson
De aanwezigheid van beide lidwoorden in het Frans is verplicht, maar het
is geen eenvoudige zaak om de regels te definiëren die beslissen in
welke gevallen er een lidwoord moet staan en - zo ja - welk lidwoord dat
moet zijn; in (25) bij voorbeeld krijgt het subject een bepaald lidwoord
maar het object een article partitif.
Een gelijkaardig probleem rijst bij de vertaling van werkwoordstijden.
Vgl.
(26) we zijn vandaag naar Brussel gekomen
(27) we zijn gisteren naar Brussel gegaan
In het eerste geval correspondeert de Nederlandse voltooid tegenwoordige
tijd met een Engelse present perfect, maar in het tweede geval met een
simple past:
(28) we have come to Brussels today
(29) * we have gone to Brussels yesterday
we went to
Brussels yesterday
| |
| |
Hoe worden deze problemen nu aangepakt?
Voor de behandeling van lexicale ambiguïteiten wordt meestal gebruik
gemaakt van semantische kenmerken, zoals [+/- levend wezen] en [+/-
mens]. Aan de hand van die kenmerken kan men bij voorbeeld de twee
betekenissen van paard onderscheiden:
| paard [+ levend wezen] |
→ horse |
| paard [- levend wezen] |
→ knight |
Men kan ze ook gebruiken om de verschillende contexten te definiëren van
essen en fressen:
| essen < subject: |
[+ levend wezen, + mens], |
object: _> |
| fressen < subject: |
[+ levend wezen, - mens], |
object: _> |
Semantische kenmerken zijn dus zeker bruikbaar en stellen computationeel
ook geen grotere problemen dan morfo-syntactische kenmerken zoals
persoon, getal en genus. Problemen ontstaan echter als men ze consequent
op de hele woordenschat wil toepassen. Zo is het bepalen van het genus
voor alle substantieven weliswaar een saaie taak, maar wel een
beslisbare, terwijl men over de toekenning van het kenmerk [+/- levend
wezen] aan substantieven soms eindeloos kan twisten. Is parlement bij voorbeeld [+ levend wezen] of [- levend wezen]?
De oorzaak van die moeilijkheden is dat genus een kenmerk is van
substantieven, terwijl [+/- levend wezen] een kenmerk is van datgene
waarnaar een substantief verwijst; het betreft dus geen linguïstische
eigenschap en de toekenning ervan aan linguïstische elementen is dan ook
problematisch.
Een tweede probleem betreft de keuze van de semantische kenmerken; dat
[+/- levend wezen] en [+/- mens] relevante onderscheidingen zijn wordt
meestal niet in twijfel getrokken, maar ze volstaan niet om alle
relevante onderscheidingen uit te drukken. Zo kan het Nederlandse paard niet alleen naar een [- levend] schaakstuk
verwijzen, maar ook naar een [- levend] gymnastiektoestel, een vaulting horse in het Engels. Betekent dat nu dat we
ook kenmerken als [+/- schaak] en [+/- gymnastiektoestel] moeten opnemen
in de verzameling van semantische distincties? En moeten die dan aan
alle substantieven in het lexicon toegekend worden?
| |
| |
Op dit moment worden er voor de behandeling van lexicale ambiguïteit twee
methodes gevolgd. De eerste vertrekt van intuïties over welke
onderscheidingen relevant zijn en concentreert zich op de ontwikkeling
van criteria voor de definitie en systematische toepassing van die
onderscheidingen. De tweede vertrekt van bestaande woordenboeken, zowel
verklarende als vertaalwoordenboeken, en tracht de informatie die daarin
opgeslagen is bruikbaar te maken voor integratie in vertaalsystemen; men
onderzoekt met andere woorden de herbruikbaarheid van bestaande lexica.
Voor de behandeling van grammaticale elementen in vertaling wordt
geëxperimenteerd met interlinguale oplossingen. Dat betekent dat
elementen als lidwoorden en hulpwerkwoorden niet in transfer worden
afgebeeld op doeltaalequivalenten, maar dat ze in de monolinguale
modules (analyse en synthese) worden afgebeeld op semantische
representaties. In de mate dat die laatste universeel zijn, kunnen ze in
transfer gewoon gekopieerd worden. Voor een concreet voorbeeld van zulk
een analyse verwijs ik naar Van Eynde, 1991.
| |
1.5 Tekstanalyse
Helemaal moeilijk wordt het wanneer de informatie die men voor het kiezen
van de juiste vertaling nodig heeft, in een andere zin staat. Dat is
vaak het geval wanneer het antecedent van een voornaamwoord moet worden
opgezocht. In
(30) De bavianen eten vandaag geen bananen.
Ze hebben
immers nog geen honger.
is het antecedent van het persoonlijk voornaamwoord ze
gelijk aan het subject van de eerste zin, de bavianen,
en aangezien het equivalent van baviaan in het Frans
mannelijk is, correspondeert ze met een mannelijke
vorm van de derde persoon:
(31) Les babouins ne mangent pas de bananes aujourd'hui.
Ils n'ont pas encore faim.
| |
| |
Als het antecedent echter gelijk is aan het object van de eerste zin,
zoals in
(32) De bavianen eten vandaag geen bananen.
Ze zijn
immers nog niet rijp.
dan correspondeert ze, aangezien het equivalent van banaan vrouwelijk is, met een vrouwelijke vorm van de
derde persoon:
(33) Les babouins ne mangent pas de bananes aujourd'hui.
Elles ne sont pas encore mûres.
Deze voorbeelden tonen aan dat men voor de juiste vertaling van
persoonlijke voornaamwoorden het antecedent ervan moet kunnen
terugvinden; sprekers van het Nederlands hebben daar geen moeite mee,
maar het valt niet mee om de regels die ze daarbij (onbewust) gebruiken
expliciet te maken en zo te formuleren dat een automaat ze kan
toepassen.
Het onderzoek in dit domein staat nog in zijn kinderschoenen. Er zijn wel
een aantal interessante observaties en descripties voorhanden, maar een
formele en computationeel bruikbare behandeling is vooralsnog niet
beschikbaar.
| |
2. Een historisch overzicht
| |
2.1 Twee generaties
In de relatief korte geschiedenis van de automatische vertaling kan men
twee generaties onderscheiden.
De systemen van de eerste generatie worden gekenmerkt door de afwezigheid
van taalkundige analyse: brontaalzinnen worden woord-voor-woord op
doeltaalzinnen afgebeeld en waar dat tot problemen leidt in verband met
de woordorde of de woordkeuze, worden die ad hoc opgelost [conform
voorbeeld (5-6)].
Een tweede kenmerk van die systemen is het gebruik van programmeertalen
die nauw aansluiten bij de machinetaal. Dat was geen bewuste keuze: men
| |
| |
moest in die dagen - de jaren vijftig - roeien met de
riemen die men had en dat waren nu eenmaal programmeertalen die meer
geschikt zijn voor wiskundige dan voor taalkundige toepassingen.
Het eerste kenmerk - afwezigheid van taalkundige analyse - was een gevolg
van de onderschatting van het vertaalprobleem. De opvatting van
vertaling als decodering van geheimtaal mag dan al een inspirerende
metafoor geweest zijn, als uitgangspunt voor de constructie van grote
vertaalsystemen is zij ongeschikt gebleken: de relatie tussen het regent en tneger teh bij
voorbeeld is van een heel andere aard dan die tussen het
regent en it is raining. Naarmate dit steeds
duidelijker werd, ging de automatische vertaling een andere weg op. Van
de ontwikkeling van grootschalige woord-voor-woord vertalers schakelde
men over op de studie van taalkundige modellen die een degelijker aanpak
van de vertaalproblemen mogelijk zouden maken:
[...] by the mid-sixties most Machine Translation researchers
were beginning to move along the path of learning how language operates
and of attempting to incorporate the results of their research into the
design of automatic procedures for the translating processes.
(Josselson, 1971)
In de praktijk heeft dit onderzoek geleid tot de toevoeging van
syntactische analyse- en synthesemodules aan vertaalsystemen. De eenheid
van vertaling was niet langer het woord maar de geanalyseerde zin en
voor de analyse en synthese van die zinnen werden modellen gehanteerd
uit de theoretische taalkunde. Die belangstelling voor de taalkunde had
een dubbele oorzaak: naast het besef dat men zonder taalkundige analyse
geen echte vorderingen kon maken, was er het feit dat de taalkunde in
die dagen steeds meer geformaliseerd en gemathematiseerd werd. Vooral
onder invloed van Noam Chomsky kreeg de studie van de wiskundige
eigenschappen van syntactische theorieën grote aandacht, ook vanwege
taalkundigen.
Tegelijk en onafhankelijk van die evolutie deden er zich in de
computerwetenschap nieuwe ontwikkelingen voor die leidden tot de creatie
van zogenaamde hogere programmeertalen. Dat zijn talen die minder nauw
aansluiten bij de machinetaal, maar flexibeler zijn in het gebruik en
een geschikter formaat bieden voor de formulering van taalkundige
regels. Voorbeelden van | |
| |
zulke talen zijn Algol, Pascal en
Prolog. Het duurde dan ook niet lang voor ze gebruikt gingen worden bij
de ontwikkeling van vertaalsystemen.
Beide evoluties - het gebruik van syntactische modellen en van hogere
programmeertalen - zijn kenmerkend voor systemen van de tweede
generatie.
| |
2.2 De huidige stand van zaken
Op dit moment biedt het domein van de automatische vertaling een
gediversifieerde aanblik. In zijn overzichtsartikel, A
survey of machine translation: its history, current status and
future prospects, onderscheidt Jonathan Slocum drie soorten
vertaalsystemen.
Ten eerste zijn er de produktiesystemen. Die zijn momenteel op de markt
en worden dagelijks door vertalers gebruikt. De meeste ervan behoren tot
de eerste generatie en vertonen daar ook alle tekorten van, maar het
feit dat ze gebruikt worden, bewijst dat ze kostenbesparend werken. De
cruciale vraag bij de evaluatie van zulke vertaalsystemen is immers niet
of ze perfecte vertalingen produceren, maar veeleer of ze het de
(menselijke) vertaler mogelijk maken om sneller, efficiënter of
accurater te werken. Als de tandem mens-machine beter functioneert dan
de mens in zijn eentje, dan heeft de machine zijn waarde bewezen.
Ten tweede zijn er de systemen in ontwikkeling. Dat zijn
produktiesystemen in wording. Ze zijn meestal gebaseerd op de principes
van de tweede generatie en stellen produkten in het vooruitzicht voor de
jaren negentig.
Ten derde zijn er de systemen die niet meteen voor grootschalige
ontwikkeling en produktie bedoeld zijn, maar waarin geëxperimenteerd
wordt met nieuwe computationele technieken, met tekstmodellen en met
systematische semantische analyse. Slocum noemt ze de
onderzoekssystemen. Het kan nog lang duren voor zulke experimentele
systemen en prototypes het stadium van de ontwikkeling en de produktie
bereiken, maar het kan ook snel gaan. Zowel het onderzoek als het vinden
van geldschieters voor dat onderzoek zijn activiteiten waarvan de
uitkomst niet geheel voorspelbaar is.
| |
| |
| |
Bibliografie
| chomsky, n.
Syntactic structures. Mouton, 1957. |
| durand, j., p. bennett, v. allegranza, f. van eynde, l.
humpreys, p. schmidt en e. steiner. ‘The Eurotra Linguistic
Specifications: An Overview’, in: Machine Translation,
6 (1991), p. 103-147. |
| eynde, f. van. ‘Automatische vertaling: een
overzicht van veertig jaar onderzoek en een blik in de toekomst’, in:
Linguistica Antverpiensia, XX (1986), p. 151-204. |
| eynde, f. van. ‘The semantics of tense and aspect’,
in: Natural Language Processing. Lecture notes in
Artificial Intelligence, Volume 476 (1991), p. 158-184. |
| josselson, h. ‘Automatic translation since 1960. A
linguist's view’, in: Advances in Computers, 11
(1971), p. 1-58. |
| slocum, j. ‘A survey of machine translation: its
history, current status and future prospects’, in: Computational Linguistics, 11 (1985), p. 1-17. |
| tsujii, j. ‘Future directions of machine
translation’, in: Proceedings of the Coling
Conference, Bonn, 1986, p. 655-668. |
| weaver, w. ‘Translation’, in: Locke en Booth [eds],
Machine translation of languages, Wiley, New York,
1949, p. 15-23. |
| De belangrijkste tijdschriften voor automatische vertaling zijn Machine Translation (Kluwer), Computational Linguistics (Association of Computational
Linguistics) en Studies in Machine Translation and Natural
Language Processing (Commission of the European
Communities). |
|
|
