
Het denken van den schaker
(1946)–A.D. de Groot–B. Numerieke Structuurgegevens en hun Variatie.De volgende paragrafen bevatten de belangrijkste resultaten van de statistische verwerking, die ik met afzonderlijke kenmerken der uitwendige structuur heb uitgevoerd. Zelf neig ik er zeker niet toe de beteekenis der gevonden getallen te overschatten, vooral niet wat § 35 betreft; m.i. heeft de lezer er echter recht op van de frequentie en variatie van allerlei verschijnselen en hun afhankelijkheid van stelling en proefpersoon iets af te weten. In al te veel publicaties, vooral in ‘geesteswetenschappelijk’ georienteerde, wordt een dergelijke quantitatieve verantwoording achterwege gelaten. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 87]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 35. Algemeene gegevens.In de eerste plaats levert ieder protocol een aantal uiterlijke, algemeene gegevens op, die voor een statistische verwerking in aanmerking komen: denktijd, protocollengte, lengte der eerste phase, en daarvan afgeleide grootheden. De denktijd werd, zooals bekend, grofweg als aantal minuten TGa naar margenoot+ geregistreerd, de protocollengte werd uitgedrukt in het aantal regels RGa naar margenoot+ van het protocol, eveneens een grove, maar voor een ruwe orientatie voldoende nauwkeurige mate (om een beeld te krijgen van de gemiddelde regellengte zie men (M2; B), blz. 74); de lengte der eerste phase in het aantal regels rGa naar margenoot+; dat deze beslaat. De gevonden gemiddelden worden in het volgende aangeduid als T̄, R̄, r̄Ga naar margenoot+, enz. Het aantal per serie verwerkte gevallen kGa naar margenoot+ is hierbij niet altijd hetzelfde, omdat soms bij afzonderlijke berekeningen bepaalde, op afwijkende wijze verkregen protocollen moesten worden uitgeschakeld; zoo b.v. de interruptie-protocollen en het tweede deel der B-protocollen (zie § 28) voor de berekening van r̄. De maximale waarde van k is 49, daar de hoofdserie in zijn geheel 43 protocollen bevat, waarvan er 6 voor bepaalde berekeningen dubbel tellen, namelijk die van de B-serie. Behalve de gemiddelden heb ik in het volgende soms ook de gemiddelde variaties aangegeven. Zoo beteekent b.v. v (T)Ga naar margenoot+: het gemiddelde der, steeds positief in rekening gebrachte, afwijkingen der individueele tijden in een bepaalde serie, van het gemiddelde T̄ van die serie. Deze gemiddelde variatie kunnen we ook in procenten van T̄ uitdrukken, om een vergelijking met de spreiding in andere series of van andere grootheden mogelijk te maken; voor de procentueele variatie V (T)Ga naar margenoot+ geldt: V (T) = 100 × v (T): T̄. De denktijd T en de protocollengte R zijn op zichzelf betrekkelijk weinig zeggende gegevens. De denktijd heeft een zekere beteekenis als ruwe maatstaf voor de moeite, die de proefpersoon zich heeft willen en moeten getroosten om tot de weloverwogen keuze van een zet te komen, en is verder nogal eens van belang als aanvullend gegeven, bij de beschouwing van andere structuurkenmerken. Zoo b.v. tezamen met de, overigens weinig belangwekkende, protocollengte: het quotient R : T = SGa naar margenoot+, dus het aantal regels tekst, dat de proefpersoon gemiddeld per minuut produceert, is een grove maat voor zijn spraakzaamheid bij het experiment - die in bepaalde gevallen van beteekenis kan zijn bij de beoordeeling van betrouwbaarheid en volledigheid van den tekst. In tabel 1 vindt men de gemiddelden van deze drie grootheden, voor de series afzonderlijk en voor het geheele materiaal, bijeengebracht. De denktijd blijft gemiddeld om en nabij het kwartier, de protocollengte beloopt gemiddeld 30 à 45 regels, terwijl S̄ dienovereenkomstig tusschen 2 en 3 (regels per minuut) ligt. De gemiddelden per serie zijn niet strikt vergelijkbaar - behalve die voor B1 en B2 onderling - door het gedeeltelijk verschillende proefpersonenmateriaal. Dat neemt echter niet weg, dat b.v. een uitgesproken groot verschil in moeilijkheid van de opgave in de grootte-orde van T̄ tot uiting zou kunnen komen. Zulke verschillen zijn er blijkbaar niet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 88]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Dat T̄ (B2) het kortste is, kan men o.a. toeschrijven aan de overbodigheid van een eerste phase; dat T̄ (C) het langste is, aan het feit, dat stelling C van objectief schaakstandpunt inderdaad moeilijk goed te beoordeelen en te behandelen is. De schommelingen in R̄ loopen ongeveer parallel met die in T̄; de spreiding der S̄-waarden is gering. Dat S̄ (rest) wat hooger uitvalt, ligt waarschijnlijk aan het feit, dat in de rest-serie ten deele reeds eenigszins geoefende proefpersonen aan het woord waren, die bovendien o.a. òm hun geschiktheid als proefpersoon, dus mede om hun ‘spraakzaamheid’ voor verdere experimenten waren aangezocht. De spreiding der T- (en R-) waarden om deze gemiddelden is zeer groot en weerspiegelt bijna die der denktijden in de wedstrijdpractijk, die, zooals bekend, schommelen tusschen een onderdeel van een seconde en meer dan een uur. Zoo zijn bij de heterogene restserie de gemiddelde variatie v (T) = 7,4 (min.), d.i. 53 % (V(T) = 53), ende uiterste waarden 3 min. (M2; a6) en 35 min. (M5; Lh7). Dat de onderste grens niet nòg lager ligt, moet worden toegeschreven aan de noodzakelijkheid van een eerste phase bij de gegeven experimenteele opstelling: de stellingen zijn geheel nieuw. Inderdaad komt in de B2-serie, waar dit niet het geval is, éénmaal T=o voor: pp. O2 denkt slechts een onderdeel van een minuut over zijn zet na. Verder treden in de speciale serie ‘combinatie-opgaven’ (zie § 28) eveneens kortere tijden op, b.v. van ½ minuut in (Tg2:). De spreiding der denktijden bij één stelling is uiteraard wat kleiner, maar toch ook nog aanzienlijk. Bij de 19 A-protocollen vinden we als extremen 6 min. (pp. G1) en 28 min. (ppn. D2 en O5), terwijl v(T) = 5,9 (min.), d.i. 39 %. Hier werken de verschillen in klasse overigens de groote spreiding in de hand: de gemiddelde denktijd der 5 grootmeesters is minder dan 10 minuten, die der 6 ppn. van de D- en O-klasse tezamen meer dan 20 minuten. Deze verschillen laten zich gemakkelijk verklaren; zij kwamen trouwens al eerder ter sprake. De spreiding in de S-waarden is over het algemeen tamelijk gering vergeleken bij die in R en T. Zoo vinden we b.v. voor de A-serie naast elkaar voor R en S: R̄ = 35,4 ± 14,5 regels: v(R) = 14,5 d.i. 41 %, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 89]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
een twee à driemaal zoo kleine spreiding dus voor S. Bij de G- en M-ppn. liggen in de A-serie alle S-waarden tusschen de 2,3 en 2,9 regels per minuut, met één uitzondering (pp. G5 niet S = 4,3!); bij de H-proefpersonen is de spreiding iets grooter, maar het gemiddelde ongeveer even hoog; bij de D- en O-klasse daalt het gemiddelde tot 2,0. Er is dus wel eenige afhankelijkheid van de klasse te constateeren, echter in veel mindere mate dan bij den denktijd T. De spraakzaamheid hangt minder van de speelsterkte af dan van meer algemeene eigenschappen van de proefpersoon, zooals het gemak, waarmee hij zich in het algemeen uitdrukt, en dgl. Daarin ontloopen de proefpersonen elkaar blijkbaar niet al te veel - met enkele uitzonderingen, zooals b.v. pp. G5 en D2. De eerste produceert, in de protocollen der stellingen A, B1, B2 en C, gemiddeld 3½ regel per minuut, de laatste 1½ regel per minuut. Voor het overige liggen de S-waarden voor de groote meerderheid der protocollen tusschen de 2 en 3 regels per minuut. De omvang der eerste phase laat zich op drie manieren uitdrukken, nl. absoluut, procentueel en volgens den geschatten tijdsduur. De procentueele omvang pGa naar margenoot+ laat zich gemakkelijk berekenen: p = 100 × r: R, terwijl de tijdsduur tGa naar margenoot+ te schatten is op t = T × r: R - in de veronderstelling, dat de proefpersonen in de eerste phase gemiddeld even veel en snel spreken als verder in het denkproces. Of dit inderdaad het geval is, heb ik niet kunnen nagaan. Daardoor, en door andere onzekerheden, zooals die bij het vaststellen van de grens tusschen eerste phase en hoofddeel, hebben de volgende getallen alleen een zeer ruwe, oriënteerende beteekenis. De afzonderlijke gemiddelden voor de series B1 en C (B2 valt uit), hier bestaande uit resp. 3 en 4 protocollen, heb ik daarom maar niet weergegeven. In tabel 2 heb ik me beperkt tot de A-protocollen eenerzijds, en die van de series B1, C en de rest-serie tezamen anderzijds.
Blijkbaar beslaat de eerste phase gemiddeld 7 à 8 regels, d.i. in doorsnee ⅕ à ¼ van de geheele protocollengte en duurt zij naar schatting gemiddeld ruim 3 minuten. Noemenswaardige verschillen tusschen de A-serie en de heterogene rest zijn er nauwelijks; ook de getallen voor de spreiding ontloopen elkaar weinig. Bezien we alléén de A-serie, dan blijkt de hooge spreiding hier weer ten deele een gevolg te zijn van de klasse-verschillen tusschen de proefpersonen. Dit geldt in het bijzonder voor t: de sterke spelers hebben aanzienlijk minder tijd noodig voor de eerste phase en ontloopen elkaar weinig. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 90]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Schakelen we de D- en O-proefpersonen uit, dan vinden we voor de resteerende groep van 12 ppn. (5 G, 2 M en 5 H): t̅ = 2,4 min. ± 0,5 min. (d.i. 22 %). Een aanzienlijk lager gemiddelde en een bijna tweemaal zoo kleine procentueele spreiding dus. Tenslotte nog de extreme waarden van r, p en t in de A-serie en over het geheele materiaal genomen (tusschen haakjes):
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 36. Statistiek der oplossingsvoorstellen.Een geheele serie numerieke structuurgegevens laat zich afleiden uit de formule der opeenvolgende oplossingsvoorstellen in engeren zin, die in dit hoofdstuk reeds voor (M2; B) werd opgesteld. Nemen we nu nog als voorbeeld het protocol (O2; A). Na de eerste phase vinden we achtereenvolgens beschouwingen en berekeningen van de volgende zetvoorstellen: 1. Pd5:; 1. Pd5:; 1. Pd5:; 1. h4; 1. Tc2; 1. Pd5:; 1. Lh6; 1. h4; 1. Lh6; 1. Lh6. Dan, na 16 minuten, wordt inderdaad 1. Lh6 gespeeld. Deze serie zetten weerspiegelt uiteraard het verloop van het denken maar zeer gedeeltelijk, vooral omdat de oplossingsvoorstellen in ruimeren zin (plannen, samenvattingen) en de tusschenliggende overgangsphasen ontbreken, maar bevat toch ook op zichzelf reeds interessante structuurgegevens, die het voordeel hebben, dat zij voor statistische verwerking vatbaar zijn. Wanneer we de verschillende in stelling A gespeelde zetten door vast eraan toegevoegde letters weergeven (zoodanig, dat in groote trekken de belangrijkste zetten door de eerste letters, en de minder belangrijke door de latere letters van het alphabet worden voorgesteld), dan wordt de formule van (O2; A): c - c - c - f - l - c - e - f - e - e - e.De slotschakeling is hier cumulatief, evenals in (M2; B2), maar anders dan in (M2; B1), d.w.z. de het laatst onderzochte zet (e, d.i. 1. Lh6) wordt ook gespeeld. Pp O2 maakt in het geheel 10X een in het protocol duidelijk onderscheidbaar begin of herbegin met een zet-onderzoek of met een betrekkelijk zelfstandig onderdeel daarvan. Dit aantal zal ik het aantal oplossingsstooten NGa naar margenoot+ noemen.. Nu treden echter in het begin bij c en later bij e herhalingen van eenzelfden zet op: 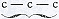 c - c - c en c - c - c en 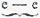 e - e. Dit zijn gevallen van voortgezet
onderzoek. Wanneer we zulke herhalingen bij elkaar denken en vragen
naar het aantal malen, dat de proefpersoon overgaat tot het onderzoek van
een nieuwen, althans van een anderen zet, welk aantal ik het aantal opeenvolgende oplossingsvoorstellen nGa naar margenoot+ zal noemen, dan vinden we e - e. Dit zijn gevallen van voortgezet
onderzoek. Wanneer we zulke herhalingen bij elkaar denken en vragen
naar het aantal malen, dat de proefpersoon overgaat tot het onderzoek van
een nieuwen, althans van een anderen zet, welk aantal ik het aantal opeenvolgende oplossingsvoorstellen nGa naar margenoot+ zal noemen, dan vinden we | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 91]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
hier dus n = 7. N is dus altijd grooter dan of gelijk aan n. In het verschil N - n = vGa naar margenoot+ bezitten we nu een grove numerieke maat voor den omvang van het verschijnsel voortgezet onderzoek in het protocol. In (O2; A) is dus v = 3, d.w.z. drie ‘oplossingsstooten’ zijn te qualificeeren als voortgezet onderzoek. Naast N en n kunnen we nu nog het aantal beschouwde zetten n0Ga naar margenoot+ onderscheiden, d.i. het aantal in de formule voorkomende letters. n0 is steeds kleiner dan of gelijk aan n; treedt onder de oplossingsvoorstellen meer dan eens eenzelfde zet (letter) op, dan is n0 kleiner dan n. In dat geval spreken we van ‘heronderzoek-met-tusschenschakeling’ (n.l. van andere oplossingsvoorstellen). Het verschil n - n0 = hGa naar margenoot+ is dus een grove maat voor den omvang van het verschijnsel heronderzoek-met-tusschenschakeling in het protocol. In (O2; A) is n = 7 en n0 = 4, dus h = 3, d.w.z. drie oplossingsvoorstellen zijn te qualificeeren als heronderzoek-met-tusschenschakeling (eenmaal c, eenmaal f en eenmaal e). De grootheden v en h geven nog geen beeld van de verdeeling der gevallen van voortgezet- en heronderzoek over verschillende zetten. Als h = 3, dan kan dit beteekenen, dat er, zooals in (O2; A), bij drie verschillende zetten elk eenmaal heronderzoek met tusschenschakeling optreedt, maar ook, dat de proefpersoon driemaal op één zet terugkomt, die dan dus in het geheel viermaal afzonderlijk voorkomt (zie b.v. de formule van (M1; A); blz. 129). Daarom heb ik nog enkele getallen uit de formule afgeleid: nv en nhGa naar margenoot+ zijn de aantallen zetten, waarbij voortgezet- resp. heronderzoek optreedt - dus voor (O2; A) is n v = 2 en n h = 3; mvGa naar margenoot+ is het maximum aantal opeenvolgende oplossingsstooten binnen één oplossingsvoorstel - dus voor (O2; A) is m v = 3, wegens het begin c - c - c; mhGa naar margenoot+ is het maximum aantal malen, dat eenzelfde oplossingsvoorstel optreedt - dus voor (O2; A) is m h = 2, daar c, f en e alle drie niet meer dan tweemaal separaat in de formule voorkomen. De drie grootheden v, n v en m v tezamen geven een aardig beeld van omvang en geaardheid van het verschijnsel voortgezet onderzoek in het protocol. Evenzoo h, n h en m h voor heronderzoek-met-tusschenschakeling. De hier onderscheiden grootheden N, n, n0; v, n v , m v ; h, n h , m h hangen onderling samen door een aantal gelijkheids- en ongelijkheidsbetrekkingen, waarvan ik hier volledigheidshalve de belangrijkste vermeld.
Wanneer dus in een protocol heronderzoek noch voortgezet onderzoek optreedt, is N = n0.
Als v = o is, dan is n v = o en m v = 1 is v = 1, dan n v = 1 en m v = 2. Voor hoogere v-waarden zijn er meer mogelijkheden: b.v. als v = 2 is, dan òf n v = 1 en m v = 3, òf n v = 2 en m v = 2. Enz. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 92]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Hieronder volgen eenige resultaten van de statistische verwerking der bovenvermelde grootheden. Allereerst de gemiddelden voor N, n en n0 bij de verschillende series. Bij de series A, B1, B2 en C heb ik bovendien ter vergelijking de reglementaire keuzevrijheid KGa naar margenoot+, d.i. het aantal volgens de spelregels mogelijke zetten (zie § 7), en het totaal aantal door alle k proefpersonen tezamen overwogen zetten, mGa naar margenoot+, toegevoegd. (m is dus tevens het aantal letters van het alphabet, dat men voor het opstellen van een vast systeem van zet-letter-toevoegingen noodig heeft bij het protocollen-materiaal van een bepaalde stelling). De eerste kolom van tabel 3 bevat tenslotte de aantallen protocollen k, waarover de gemiddelden N̄, n̅ en n̅0 en de totalen m werden berekend.
Uit de tabel laat zich in de eerste plaats aflezen, dat de proefpersonen gemiddeld niet meer dan 4 à 5 verschillende zetten in overweging nemen (n0), een aantal, dat klein is niet alleen t.o.v. het aantal reglementair toegestane zetten (K), maar ook t.o.v. het aantal door allen tezamen beschouwde zetten (m). Op deze ‘onvolledigheid’ in de afwerking der zetmogelijkheden kom ik nog terug. De waarden van N, n en in mindere mate ook van n0 hangen natuurlijk per protocol samen met den denktijd, en dus ook per serie met den gemiddelden denktijd. Vandaar waarschijnlijk de hooge gemiddelden bij de C-serie, waar immers de gemiddelde denktijd het hoogste was. Blijkbaar kunnen we bij deze denkprocessen van gemiddeld een kwartier of, na aftrek van de eerste phase, van 12 minuten tijdsduur rekenen met gemiddeld 8 oplossingsstooten en 6 oplossingsvoorstellen, d.w.z. de proefpersoon begint gemiddeld eens in de 1½ minuut opnieuw met een relatief zelfstandig stuk onderzoek (berekening) en hij gaat gemiddeld eens in de 2 minuten over tot de beschouwing van een anderen zet (niet noodzakelijk een nieuwen, nog niet eerder beschouwden, zet). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 93]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Aangezien 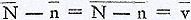 , en evenzoo n̅ - no̅ = h̄, kunnen we uit tabel
3 onmiddellijk de bijbehoorende waarden van v̅ en h̄ afleiden. De som van v̅
en h is verder gelijk aan N̄ - n̅0̅. Bij vergelijking
der kolommen zien we, dat N̄ bijna tweemaal zoo groot is als n̅̅; het verschil beloopt in doorsnee ongeveer 4. Dat werpt in
ieder geval reeds eenig licht op het groote quantitatieve
belang van voortgezet onderzoek en heronderzoek tezamen. , en evenzoo n̅ - no̅ = h̄, kunnen we uit tabel
3 onmiddellijk de bijbehoorende waarden van v̅ en h̄ afleiden. De som van v̅
en h is verder gelijk aan N̄ - n̅0̅. Bij vergelijking
der kolommen zien we, dat N̄ bijna tweemaal zoo groot is als n̅̅; het verschil beloopt in doorsnee ongeveer 4. Dat werpt in
ieder geval reeds eenig licht op het groote quantitatieve
belang van voortgezet onderzoek en heronderzoek tezamen.
Wanneer we het materiaal zelf beschouwen dan blijkt overigens de verdeeling der getallen N - n0 scheef te zijn. De mediaan is 3; het gemiddelde wordt eenigszins omhoog gehaald door sommige extreme gevallen. Zoo wordt in de A-serie tweemaal de waarde N - no = 9 en éénmaal 8 bereikt; de hoogste waarden vinden we echter in de volgende drie gevallen:
Dit zijn extreme voorbeelden van heronderzoek-protocollen, zooals ook uit de grootheden in het rechterdeel van de tabel blijkt. Atypisch zijn ze overigens niet; er is door rangschikking van de protocollen van het materiaal een geleidelijke overgang naar deze gevallen te construeeren. Hooge waarden voor de v- en h-grootheden komen meer voor - zooals trouwens al volgt uit het relatief hooge gemiddelde voor v + h = N - no. De laagste waarde, die N - n0 kan aannemen, is o; in het geheele materiaal komt dit echter slechts driemaal voor.
Beschouwen we thans voortgezet onderzoek en heronderzoek-mettusschenschakeling elk afzonderlijk. Het duidelijkste beeld verschaft een frequentie-tabel voor de verschillende waarden der v- en h-grootheden:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 94]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wat het voortgezet onderzoek betreft: v = o (en dus n v = o en m v = 1) is blijkbaar een betrekkelijke uitzondering (13 %). De normale waarden zijn v = 1, v = 2 en v = 3; modus en mediaan liggen bij 2, terwijl v̅ = 2,2. Bij n v concentreert zich alles op de waarden 1 en 2, bij m v op 2 en 3. Het verschijnsel voortgezet onderzoek is dus wel vrijwel algemeen (13 % uitzonderingen); gewoonlijk worden er echter niet meer dan één of twee zetvoorstellen in meerdere opeenvolgende stooten onderzocht, terwijl het maximum aantal stooten meestal tot 2 of 3 beperkt blijft (slechts 11 % gevallen met m v = 4). Bij het heronderzoek-met-tusschenschakeling liggen de verhoudingen anders. Hier vormen de gevallen met h = o een groep op zichzelf (39 %), terwijl de hoogere waarden een geleidelijk dalende frequentie bezitten. Ook de tabel voor n h loopt meer naar beneden toe uit dan die voor n v . M.a.w.: àls het eigenaardige terugkomen op reeds eerder overwogen zetvoorstellen optreedt, dan is de kans ook relatief groot, dat dit meerdere malen of bij meerdere zetten gebeurt. Inderdaad treedt heronderzoek-met-tusschenschakeling in het algemeen alleen op als de keuze den proefpersoon moeilijk valt; maar dàn hebben we ook vaak te doen met een opbouw van het geheele denkproces in phasen van successieve verdieping. Vandaar, dat n h = 3 of 4 minder uitzonderlijk is dan n v = 3 of 4; vandaar ook de relatief nog hooge frequenties van h-waarden boven de 4. Wat tenslotte m h betreft: uit de tabel blijkt, dat het nog heel normaal is, wanneer eenzelfde zetvoorstel (of meerdere voorstellen) driemaal, met tusschenpoozen, optreedt. m h = 4 of 5 komt tezamen in 9 % der protocollen voor. Wanneer we op grond van de bovenstaaande gegevens een schatting willen maken van het quantitatieve belang van het verschijnsel heronderzoek in het algemeen, dan moeten we in aanmerking nemen, dat de h-grootheden slechts de frequentie van een deel der gevallen aangeven. In de eerste plaats komt naast heronderzoek van zetvoorstellen ook heronderzoek van plannen, afzonderlijke varianten en stellingen voor; dit kon in het geheel niet worden geregistreerd bij de gebezigde methode. In de tweede plaats zullen we later zien (§ 42), dat de gevallen van voortgezet onderzoek gesplitst kunnen worden in vervolg-onderzoek eenerzijds en heronderzoek anderzijds, maar dan zònder tusschenschakeling. Deze laatste gevallen van heronderzoek zijn dus niet in de h-grootheden, maar in de v-grootheden verwerkt. In de derde plaats kan natuurlijk de meer besproken onvolledigheid van het protocol in vergelijking met het werkelijke denkproces alleen ten nadeele van de gevonden frequenties werken. Bij een nadere beschouwing der 18 protocollen met h = o blijkt dan ook, dat meestal toch wel heronderzoek van bepaalde mogelijkheden heeft plaats gevonden, maar zonder tusschenschakeling, althans zonder uiterlijk registreerbare tusschenschakeling. De conclusie moet in ieder geval luiden, dat heronderzoek van bepaalde mogelijkheden, zoo al geen algemeen, dan toch een quantitatief uiterst belangrijk en voor het schaakdenken karakteristiek verschijnsel is. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 95]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tot besluit van deze paragraaf volgt hier nog een korte bespreking van enkele voorkomende verschillen per stelling en per proefpersoon, voor zoover deze in de behandelde numerieke grootheden tot uiting komen.
Wat het materiaal, verkregen met stelling A, betreft, verdeelingen en gemiddelden der verschillende grootheden stemmen hier vrijwel overeen met die van het geheele materiaal. Alleen h̄ is eenigszins aan den lagen kant (1,4 tegenover 1,8 als totaal-gemiddelde). Verder is het opmerkelijk, dat slechts in 2 gevallen (10 %) de slotschakeling subsidiair is - d.w.z. dat een andere zet dan de laatst onderzochte gespeeld wordt - tegenover 22 % voor het geheele materiaal. Het is hier blijkbaar een zeldzaamheid, dat de proefpersoon tenslotte via het negatieve deel der beredeneering, via vergelijking met andere zetten, tot het zetbesluit komt. Voor vele proefpersonen, in de eerste plaats voor de grootmeesters, was opgave A inderdaad een kwestie van vinden en berekenen van ‘den besten zet’ (zie § 8), waarna de relatieve argumenten van het negatieve bewijsdeel achterwege konden blijven. Alleen het positieve bewijs, dat de zet tot voordeel leidt, was voldoende. Daarmee hangt ook de lagere h̄-waarde voor de A-serie samen. In de 6 protocollen van de B-serie, eerste deel, vinden we 3-maal, d.i. dus in 50 % der gevallen, een subsidiaire eindschakeling. Hoewel het materiaal natuurlijk te klein is voor een conclusie alleen op grond van dit statistische verschil met de A-groep, hangt dit verschil zelf toch zeker met het andere karakter van stelling B samen. In de protocollen treedt, evenals bij stelling C, waar zich in 2 van de 5 gevallen een subsidiaire eindschakeling voordoet, het indirecte argument: ‘andere zetten zijn niet beter’, ‘ik zie niet veel anders’ en dgl., inderdaad veel vaker op dan bij stelling A het geval is. Verder onderscheidt zich het B1-materiaal door lage waarden van N, n, n0 (zie tabel 3) en vooral van de v-grootheden.
Er komt slechts een betrekkelijk gering aantal zetten in aanmerking, en deze vergen geen diepe berekeningen, geen voortgezet onderzoek. Het gaat minder om zetten en berekeningen dan om plannen en meer algemeene overwegingen. In stelling B2 is dat al anders: daar wijken de genoemde grootheden gemiddeld weinig van de totale gemiddelden af. Het materiaal van stelling C onderscheidt zich door hooge waarden van N̄ en n̅ (zie tabel 3) en verder vooral van v̅, n̅ v , h̄ en m̅ h :
Dus: een groot aantal oplossingsstooten, met samengestelde of zich verdiepende berekeningen (voortgezet onderzoek) bij gemiddeld twee zetvoorstellen; veelvuldig terug komen op reeds eerder overwogen zetten - tengevolge van successieve verdieping van het mogelijkhedenonderzoek en van onderlinge vergelijking van zetten. Inderdaad een serie verschijnselen, die zeker samenhangen met het bijzondere karakter van stelling C. Deze is niet objectief oplosbaar en laat zich niet goed systematisch, volgens plannen en algemeene overwegingen behandelen. Alleen via berekeningen van verschillende zetten, waarvan de resultaten tegen elkaar worden afgewogen, kan men hier tot een subjectief bevredigende keuze komen. Wat de rest-serie betreft, bij deze heterogene groep komen de gemiddelden vrijwel overeen met die van het geheele materiaal. N̄, n̅, n0̅ en v̅ en h̄ zijn eenigszins aan den lagen kant als gevolg van de aanwezigheid van enkele minder zwaarwichtige opgaven in deze serie, zooals de stellingen a6, De5 en Pd2.
Tenslotte, als illustratie van de bruikbaarheid der numerieke structuurgrootheden, een enkel woord over persoonlijke eigenaardigheden van sommige proefpersonen en over enkele bijzonderheden bij afzonderlijke protocollen. Bij sommige zwakkere proefpersonen (D- en O-klasse) treffen we bij normale tot lange denktijden en aantallen oplossingsvoorstellen (n groot) extreem lage h-waarden aan (vgl. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[pagina 96]
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
§ 49, onder 3). Zoo is in de 4 protocollen van pp. D2 slechts eenmaal h = 1, voor het overige steeds h = 0; in (D2; A) vinden we bijvoorbeeld: T = 28 min. N = 9 n = 8 n0 = 8, dus v = 1 en h = 0. Een soortgelijk beeld vertoont (D2; C) en (O5; B2): ook daar is n = n0 = 8, terwijl in het algemeen gelijkheid van n en n0 alleen bij veel lagere n-waarden en kortere denktijden optreedt. Er passeeren dus veel zetten de revue, maar de proefpersoon komt nergens op een reeds eerder overwogen zetvoorstel terug. Er is dus géén successieve verdieping van het onderzoek - wat we hier moeten interpreteeren als een tekortkoming op het punt van denkmethodiek (vgl. § 52). Pp. M2 onderscheidt zich van andere proefpersonen van dezelfde klasse door hooge waarden van N, n en n0. Zoo b.v.:
Alleen bij B2 blijft pp. M2 onder de gemiddelden; voor het overige overschrijdt hij ze verre. Waarden als N = 20 en n0 = 11 zijn uniek in het materiaal; de eerstvolgende n0-waarde is b.v. n0 = 8. Pp. M2 berekent blijkbaar meer zetten dan een ander, hij gaat minder intuïtief en volgens algemeene overwegingen te werk; hij is meer geneigd te ‘probeeren’ dan de meeste anderen (vgl. § 59). Natuurlijk is hier alleen sprake van een meer of minder, van een neiging inderdaad, niet van een onveranderlijk toegepaste methode; dit blijkt b.v. uit het protocol (M2; a6) met T = 3 min., n0 = 1 en de formule: a - a - a (vgl. § 49). -
Bij de in deze paragraaf beschreven statistische verwerking werden drie protocollen uit de hoofdserie niet meegerekend, n.l. (O2; B2), (M5; Lh7) en (M2; Kg2). Het protocol (O2; B2) bestaat uit niets anders dan het zetbesluit zelf (T = o), levert dus niets op. In (M5; Lh7) werd pp. M5, doordat hij een mogelijk geachte winnende combinatie maar niet kon vinden, tenslotte volgens eigen woorden bevangen door een ‘pathologische twijfelzucht’, die zich dan ook uitdrukt in een abnormaal hooge h-waarde (h = 12, terwijl overigens het maximum 7 is!). Wat tenslotte (M2; Kg2) aangaat, de stelling Kg2 is zoozeer uitsluitend van strategischen aard, dat het denken zich vrijwel geheel in algemeene overwegingen en plannen (oplossingsvoorstellen in ruimeren zin) voltrekt; zetvoorstellen spelen een zoo geringe rol, dat de formule en de daaruit afgeleide grootheden absoluut niet maatstafgevend zijn voor het verloop van het denken. Natuurlijk mankeert hier ook in andere gevallen en zelfs in het algemeen wel wat aan; dit extreme geval kon echter beter geheel worden uitgeschakeld. |